seedance2.0如何生成配音
为什么我说 cds 是 目前模型能力最强的视频模型呢?是因为它能够从你输入进去的东西给你一个完整可用的十五秒。这个完整可用十五秒的意思是指什么?是指你不需要再进行剪辑、配音、配乐,它给你的就是一个完整的十五秒的成片。这个是 ai 视频模型之后发展的趋势, ai 的 发电也也是这样,能省则省,能 ai 化的就 ai 化,能一次性得到最后结果的就一次性得到最后的结果。所以它的十五秒是一个完整的东西,它比可灵的十五秒得到的还不一样。可灵的十五秒只能你做分镜的设计,分界的分镜,但是它没有那么高的完成度,所以这个是他们的差别。

粉丝1550获赞8269
相关视频
 00:30查看AI文稿AI文稿
00:30查看AI文稿AI文稿兄弟们一个重大发现,所有做 tiktok 有 头流的商家现在都可以免费使用,声带是二点零,我给大家找一下入口在哪里啊?我们进入 tiktok 的 广告后台,点击这里, 稍微等待一下啊,然后你就进入这个界面,这里有视频生成图,图片生成数字人话音,混剪、翻译、配音全部都有,现在是二点零,免费的,全部免费,兄弟赶紧去试一下。
1784MY在印尼 01:54查看AI文稿AI文稿
01:54查看AI文稿AI文稿ai 慢距变线绊脚石之一就是音色同步难,角色音色不统一,不用反复调试。今天就拆解 cadence 二点零的音频参考功能,教你轻松搞定适配合规变现实操。关于 ai 短片中音色共鸣的痛点, cadence 二点零早已给出了完美解决方, 操作简单且易落地。很多创作者都忽略了,二点零不仅支持图片、视频两种参考形式,更暗藏音频参考功能,这正是实现角色音色统一,提升内容质感,进而增强变现竞争力的核心关键。话不多说,先听一段刚录制好的音频演示,死胖子, 你天天就跟 ai 过去吧,眼里还有我这个老婆吗?接下来,我们就把这段音频的音色精准赋予画面中的美女角色,步骤简单,跟着操作就能学会。 我们以还原音频中的场景为例,完整实操流程拆解留下建议,重点记好每一步。第一步,将提前准备好的人物、角色素材、场景图片以及这段参考音频一并上传至 cds 二点零后台。第二步,剧情设置,参考此前回复的相关资料。第三步,在美女角色的参数设置中添加一句关键指令,语气及音色参考对应上传音频 有个易踩坑细节需要提醒,画面中的男性角色此时处于沉默状态,无需发声,因此无需设置任何参考音色,直接标注无即可,避免出现音色干扰。所有设置全部完成,接下来我们直接看最终呈现效果。死胖子, 你天天就跟 ai 过去吧,眼里还有我这个老婆!操作就是这么高效!后续创作 ai 短片时,只需 a t t 同一段参考音频就能实现同一角色音色全程统一,大幅提升内容专业度,为变现转化加分。 现在全是 ai, ai 更实用的是,我们还能利用这段固定音色,让角色演唱粤语伤感情歌,丰富内容呈现形式,吸引更多流量。 这套音频参考实操技巧相信大家已经掌握了,今天的实操分享就到这里了,更高级的漫剧的轻创业实战库我都整理好了。老规矩点关注评论区扣装备,看主页置顶详情。
104大圣AI轻创业 05:15查看AI文稿AI文稿
05:15查看AI文稿AI文稿c 店十二点零太贵,我最近发现了一个 l t s 开源模型,它还能结合音频来生成对应的人物口型,说话以及他人物脸型也是一致的。陛下,陛下可是做了噩梦。 呃呃,被陛下呀。这里是哪里? 并且我一共抽了一百多条视频,一共充了五十七块,我还有七块钱没有用完。三条视频平均十秒钟。我先用 tts 来进行配音,然后要上传克隆音色的音频,然后输入角色要说的台词, 在用我这个参考音频,把我想要这个角色的一个语气啊,甚至一个情绪啊这个语音给先录下来,然后让这个 tts 去克隆我这个语音这个情绪,然后点击生成语音,然后下载好克隆后的音频, 再用数字人这个功能去生成对应的画面人物,然后再上传手帧图,然后我留了许多分镜手帧图来备用不同角度的我们再导入刚刚配好的音频, 然后输入画面提示词,点击生成就可以排队等待,等待一会这里会出现结果。平均一秒钟视频需要一分钟。手征图的多角度不同机位,我是用这个来生成的,我先生成一张,然后我是用里不里不里面的这个 qm 二五幺幺这个模型,点击这里, 然后上传一张图,然后调整他们的俯仰相机角度位置,全部调好之后,然后点击立刻升图。我这个是五分钱五张生成好的图片,右键点击保存即可下载。你们如果遇到工作流用不了,可以点击这里,点成 yes 就 能使用。 我平时也会让豆包根据一个图片生成不同的分镜,豆包挺好用的,免费。我这里是抽出了三个镜头,然后做出不一样的分镜角度。像吉梦那样。正义已决,胆敢有异志者可以辞官还乡。 推行词二,法者,重重有赏,阳奉阴违者斩。具体的模型部署教程私信幺幺幺,我来告诉你。流程非常简单,云端部署,一个小时能生成四条视频,一个小时二点七块钱,我还给你 t t s 模型的整合包以及八百个音色的集合,求你点个赞吧!我现在失业状态,这是我的工作经验,谢谢。后面是我的长篇。坐标广州,有没有老板要我的?保护私有财产引进技术进行工业革命, 明朝世界经济的主导者。哎呀,陛下,陛下可是做了噩梦。呃呃,被陛下呀。 这里是哪里? 我我是朱元璋,我我超越成了朱元璋。 快快拿奏折给我。 不行,太慢了,还是我自己去吧。红武三年好,明朝刚刚建立,一切都在起步阶段,现在我可以直接发布法令, 专利法、私有产权保护法,开放港口,引进玻璃精炼炉、切割机。 既然老天让我穿越,那我就要改变整个民族的命运, 吾王万岁万万岁!有事启奏,无事退朝,慢着,朕有旨要发布,臣等聆听圣训。 即日起发布工匠专利保护令,凡天下工匠有发明创造者可向官府申请专利,使用者需缴纳专利费给予发明者。 这很少会有啊,在班私有财产保护率反百姓合法所得之田产、房屋、金银皆为私产,神圣不可侵犯。陛下此举恐怕有失支持, 朕意已决,胆敢有异意者可以辞官还乡,推行此二法者,重重有赏,阳奉阴违者斩。可是陛下 阻制啊!阻制朕才是太祖大明的未来,由朕来书写退朝。
234积木飞升 01:47查看AI文稿AI文稿
01:47查看AI文稿AI文稿如何解决 ai 短片中角色音色不一致问题?其实这个问题 cds 二点零已经彻底帮我们解决了。二点零除了支持图片视频参考外,其实它还支持音频参考。先听听这条刚录的声音,死胖子 天天, ai, ai 眼里还有我这个老婆吗?你干脆就和 ai 过一辈子去吧! 现在将这条音色赋予这个美女,要做什么呢?我要还原刚刚音频中发生的事情。整个过程如下,将他丢给 cds 二点零,人物角色场景图以及参考音频也一同传上去。在剧情前面艾特对应的参考素材, 在对应的人物后面加上这句话,语气和音色参考对应音频,男人此时已丧失发言权,不配说话,也不敢说话,所以参考音色无现在发送出去,我们来看看怎么肥四吧! 死胖子天天, ai, ai 眼里还有我这个老婆吗?你干脆就和 ai 过一辈子去吧! 声音参考就是这么简单,当我们在创作下个视频时,爱的相同音频就能完美保持角色音色一致。我真是怎么会看上这个死胖子,当初,当初还说要陪我一辈子, 现在现在全是 ai, ai 甚至还能让他使用这个音色用粤语唱着伤心情歌, 现在你学会了吗?那问题来了,现在这种情况我该怎么办?请支个招,在线等急!
2369AIGC自修室 01:02查看AI文稿AI文稿
01:02查看AI文稿AI文稿你有没有刷到过这些万赞的爆款视频?现在你也能一键复刻,他们直接发到自己的账号上。首先复制视频链接,然后转到小云雀,进入沉浸式短片,把刚才的链接粘贴进去。或是直接上传本地视频, 他就会自动学习视频里的画面风格、运镜动作、字幕旁白,写出一份超详细的分镜脚本, 然后一次性生成最长十五秒的视频,你看是不是跟原版非常像?以前想做重爆款视频,得花大把时间研究提示词,折腾 ai 工具不停抽卡。但是现在用小圆圈的爆款复刻功能就能一键搞定,而且在最新的 cds 二点零模型加持下,生成效果也大幅提升。更绝的是这个无限续写功能, 比如我想改编这个影视剧,上传原始片段后,不断输入提示词,就能续写内容,构成一个完整的故事。哪怕是高难度的运动镜头,也依然能轻松搞定。 我今天喷了太多香水!此外啊,接入新模型后,还能一句话批掉背景、替换产品、更换划分,超级简单,你也快来试试做全网爆火的视频吧!
866树懒TV 04:11查看AI文稿AI文稿
04:11查看AI文稿AI文稿哈喽,字字动画的朋友们,今天是一期睫毛二点零的字字动画全流程操作教程,在完成软件前置设置之后,在插件这里可以看到今天使用的模型是 c, 当 c 二点零 打开创建作品,导入我们的小说原文等软件完成自动分镜之后,依次在右边点击提炼故事情节、划分章节、提取角色信息、提取物品信息 等软件。完成这些之后,在右侧角色场景物品管理处检查是否创建成功,就可以开始生成对应的图片了。这一块也可以选择自己把已有图片进行上传,自定义提示词, 今天我们做的是古风真人版,在这里演示使用的提示词是这样的,等待所有图片生成或自己上传之后,角色卡片右下方会出现一个 cds 图标, 确认无物之后,回到我们右上角第一个小方块进行提示词推理。等所有提示词推理完成之后,就可以开始进行视频生成。 我们可以看见在提示词推理之后,每段分镜都自动匹配了人物场景物品,保证了角色一致性。点击视频生成,然后就可以预览效果,确认无物之后进行下一个分镜的视频生成。 睫毛二点零支持视频参考,意味着我们可以复制上一条视频作为参考,这样能够更好的保证视频的连贯性。 视频之后依旧需要检查效果,确认无误之后进行下一步再演示两次,全部使用视频参考,保证一致性。 同时字字动画也支持极梦二点零的批量操作,这一个板块点击无视频分镜生成视频即可,等全部生成完之后,导入剪映,去掉无用片段,加入转场和 bgm 之后看一下效果。 大小姐,您就服个软吧!三老爷说了,只要您去给柳家赔个不是,这事就 赔什么,不是退婚的是他柳明轩,当众撕毁婚书的是他柳明轩,说我资质平庸不堪为配的也是他柳明轩。我赔什么不是 柳明轩,青云城第一天才,十五岁开脉,十七岁筑基,如今二十岁,已是凝气境巅峰,被苍玄宗长老亲自点名收入门下。而我,七岁开脉,十二岁筑基,然后修为就卡在了筑基境八年,从木家百年一遇的天才变成木家百年一遇的笑话, 他只用了一千四百柱香的功夫。 不要太灿烂,不要太拘谨,要刚刚好。 暮冤华,你我有婚约在身,本应是天作之合,但你修为停滞八年,资质已废,与我相差太远,强行结为道侣,与你,与我皆非姓氏。 今日柳明轩退婚, 你一个修为废了的丫头骗子,守着那间铺面有什么用?所以我就该被当成货物,明码标价换来换去。 我们生成单条视频的时间大概是十分钟到二十分钟,参考视频的价格是四百八十 p 五毛五每秒,七百二十 p 一 块二每秒。 有参考视频的价格是四百八十 p 三毛四每秒,七二零 p 八毛每秒。计费方式是每秒乘以参考视频加输出视频。今天就到这里了,朋友们还有什么疑问,记得在评论区留言。
485字字动画 01:12查看AI文稿AI文稿
01:12查看AI文稿AI文稿注意看 besties welcome back today, we're making a new slime let me show you the setup pink pigment。 这段真人 sm 二不是拍的,是 ai 做的,还记得去年 ai sm 二有多火吗?我感觉这很可能会变成下一波 ai 视频的爆点。 操作很简单,依旧是 v 二模型加 c 单词二点零这套组合。这里我用 leibu leibu 来做演示,因为它把国内很多主流模型都整合在一起了,做这种内容会比较顺手,一站式就能完成。先说第一步,生成素材,我一般会先确定角色形象,整体色彩,还有分镜画面, 这一步直接选择智能图片 v 二模型就可以了。这里大家先别着急,这三张图对应的提示词模板我已经整理好了,想要的话评论区滴滴就行。三张图做好之后,我们再切到 cds 二点零,把前面生成的图片全部上传进去, 再输入对应的视频提示词,点击生成。整个流程其实不复杂,关键就是先把人物质感和画面氛围定好,后面再交给视频模型去补动态,最后出来的效果你们看完再告诉我。第一眼会不会真的以为这是真人拍的?我给大家看看 准备的东西,粉色色粉、闪粉,还有小吊坠,一切都准备就绪好了,准备好了吗?切换服饰视角,我们开始吧!
402🍊橙以零.ai 02:02查看AI文稿AI文稿
02:02查看AI文稿AI文稿你肯定也遇到过这种 cds 二点零生成出来俩视频里的同一角色音色不一致的问题,我叫芬恩,我是云逸。哇,这感觉太棒了,今天教大家手把手解决。我们可以把生成好的一段视频导入剪映,来听听视频里的音色。 喂,等一下吃什么,我饿死了,去吃拉面吧,朕子最近新开的铺,我们适当调高视频的音量,右键视频轨道,选择分离音频, 删除视频轨道,然后把轨道分割成两部分,女生和男生,然后分别把女生和男生导出为音频文件。一定要记得把这个视频导出给删掉,仅导出音频。 导出完,我们来到这个 ai 内容制作工具,找到素材,点击上传,选择音频,把我们的两个音频文件分别上传上去, 回到首页,选择视频生成。从素材库里上传好下一段视频的参考图和参考音频, 写好提示词,并在提示词中限定角色音色的音频使用。参考 选上满写不排队的 cds 二点零模型图片参考选多参考。这次生成的是一个五秒的视频片段, 只要几分钟视频就能生成。好,我们下载好视频,把两段视频连着,看来看看音色一致不一致。喂,等一下吃什么,我饿死了,去吃拉面吧,朕子最近新开的铺巨好吃!没骗你吧, 也不用这么夸张吧,可以听出角色音色被完美复刻了,连男主嘴里塞着东西说话的嘟囔声都和原音色保持了同声线。关注我,学习更多干货!
263仙女龙AI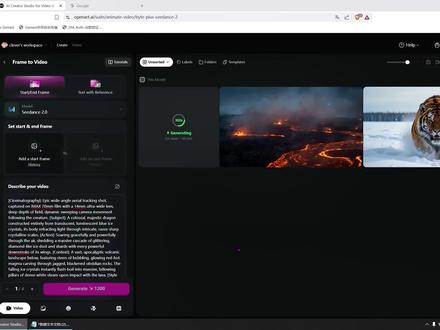 01:14查看AI文稿AI文稿
01:14查看AI文稿AI文稿今天我来教大家如何免费无限使用 cds 二点零。首先我们选择浏览器的无痕模式,我们直接复制链接进去,这里可以领两万个积分。点击领取,点击注册,注册成功即可领取两万积分。我们制作视频来试一下,选择 video, 我们选择文本转视频,这里我们可以选择很多模型,有极梦二点零,可零千问 v o, sora 等等,我们直接选择极梦二点零,复制一下提示词,打开自动认色,生成一个试一下,时间比较久,我们直接看成片。 两万积分,虽然只可以生成六个一零八零 p 十五秒的视频,但是大家不要担心,主播已经挖掘出了能够无限获取积分的方法,我们只需要更换 ip, 关闭无痕窗口,重新打开,再进入链接,使用新的邮箱注册,就可以再次领取了。主播已经领取五六个邮箱了,大家速度领,不确定有多少。关注主播,获得更多 ai 羊毛资讯。
2657UPUPUP! 00:18查看AI文稿AI文稿
00:18查看AI文稿AI文稿今天教大家制作相当火爆的 just game 对 口型视频,非常非常的简单,先戳这里,再戳这里,来到小云雀工具那点击照片跟我斗,先上传一张自己的美照,接着呢,粘贴你要复刻的爆款视频链接,点击解析,解析完之后直接点击生成就 ok 了,快去尝试一下。
100溜溜 00:57查看AI文稿AI文稿
00:57查看AI文稿AI文稿干了十四年的效果图,今天竟然被 ai 干破房了!以前这样的实景是不是要花几万去拍摄?现在呢? 根本不用这么麻烦,就算你是新手小白,十分钟也能让房子不仅仅是一个遮风避雨的地方,竟然还有台词,更是 不仅仅是一个遮风避雨的地方,而且却还在这爱,那你让我做什么?那这样的视频该怎么做呢?首先有几张空间结构完全一致的分镜,不会做分镜图的去看我上面两条视频,都是保姆级教程,我们把这些分镜图直接丢给 cds 二点零,接着你悄悄告诉他,帮我分析一下这些图片, 并且制作一个室内设计方案展示视频要有连续性和故事性,点击生成。我去,还有玩法吗?还有法律吗?这些小 bug 我 们后期通过剪辑直接修复。关注我,定期分享室内设计相关的 ai 小 技巧,让你们的效果图方案更加惊艳!
1334辣眼精 02:02查看AI文稿AI文稿
02:02查看AI文稿AI文稿最近,字节跳动旗下的火山引擎上线了 cdenys 二点零系列 a p i 服务,面向企业和个人全面开放视频生成能力。这个消息在内容创作圈引起了巨大反响。 cdenys 二点零是字节 c 研究团队推出的新一代 ai 视频生成大模型,也是极梦 ai 豆包视频 生成能力的底层核心,他在几个维度实现了跨越式升级。第一是多模态输入,支持文本、图片、音频、视频四种模态的混合输入,创作自由度非常高,你可以给他一段文字描述,也可以给他一张参考图, 甚至可以给他一段视力视频作为风格模板。第二是导演级,精准可控,他能够高度还原复杂的剧本,保障人物、场景风格在整个视频中全程一致, 支持动作运镜、复刻视频,无缝延长片段,精准编辑。这意味着专业创作者可以用它来做真正的影视级内容,而不只是有意思的 demo。 第三是音视频一 体化,搭载双声道立体声技术,可以同步生成贴合画面的多轨音频,口型匹配自然,无需额外后期处理。这一点对短视频创作者来说极其关键。过去做 ai 视频还要单独找配音、找 bgm, 现在一步到位。第四是复杂场景生 能力,稳定呈现多人交互等复杂动作,还原真实物理逻辑与画面细节,适配广告、影视、动画等全场景创作 api。 全面开放的意义比技术本身更重大,它意味着 ai 视频生成不再是少数大厂的专利,任何一个开发者、创业者甚至个人,都可以调用这套能力,构建自己的产品可以遇见的几个应用场景,电商行业,商家可以用 ai 直接生成商品,视频广 不用再找 mcn 拍摄。教育行业,老师可以用 ai 生成教学动画,把抽象的知识和视化。影视行业,独立导演可以用 ai 做分镜、做预览,大幅降低前期成本。自媒体行业,内容创作者可以用 ai 生成 短视频素材,效率提升好几倍。 ai 视频生成这个赛道过去两年进步速度惊人,从最早动不了的图片,到现在接近实拍的短视频, 技术迭代的节奏比很多人预期的都要快。当 cds 二点零这样的能力变成 a p i 开放给所有人的时候,整个内容行业的游戏规则都会发生变化。一个 ai 驱动的内容爆发时代可能真的就要到来了。
6301锐评AI要点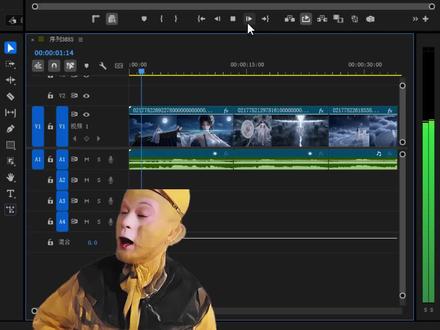 01:06查看AI文稿AI文稿
01:06查看AI文稿AI文稿cds 二点零终于可以不用苦等排队了,在 pr 里就能直接使用,生成速度更快, ai 短剧慢剧还不是轻轻松松拿捏吗?来,猴哥这就手把手教你。你就直接打开顶部窗口这个 pr 插件, 打开之后默认是文本图形插件,还能给视频识别字幕加转场,甚至 ai 配音、声音克隆、人声分离等全都有。 我们切换到视频模块里,点开这个 ai 融合生视频就能使用 c, 等于二点零了。操作很简单,这里导入我们视频的参考图,输入一下画面描述,和官网用法一样,需要输入图片一和图片二,具体的镜头描述就根据你的来写。 下面可以切换模型 c, 但是二点零和 fast 的 版本都有,其他可零,万象模型也可以直接用其他的视频参数都设置一下,就可以点生成了。生成完成后,这里可以小窗口简单预览,我们点下面的应用,可以直接导入到 pr 时间轴, 使用起来也是非常简单,还能和 pr 交互,快速生成镜头并剪辑。你就说方不方便,有没有学会吧!
22千鹿Pr助手软件 01:10查看AI文稿AI文稿
01:10查看AI文稿AI文稿也许我们能一天做出一个九十分钟电影来,一轮公司一轮剧组,慢慢会成为一个潮流的现象。过去的 ai 影视仍需要进行剪辑和配音等后期环节,如今不少流程都可以一次性完成。今日,字节跳动正式上线了新一代视频生成模型 c 档次二点零,并接入旗下生成式 ai 创作平台奇梦 豆包 app。 这款视频生成模型发布之后,凭借逼真的画面效果和简易的创作方式迅速走红。用户只需要输入简单的文字、图片或者视频,就可以生成几秒到十几秒的视频。和过往的视频生成模型相比呢,他的生成效果明显提升,画面更精准、更逼真,而且可控性也更强。 一些外国用户在实测后也惊叹,该模型能够彻底改变电影制作市场,响应特别强烈,是全球的反应都很强烈,每天都有很多这个用户来,甚至有很多这个外国 我的朋友,他自带翻译软件啊,来学习怎么用。火山引擎是自己跳动面向企业的云与 ai 服务平台,也是今年总台春晚独家 ai 云合作伙伴。在 cds 二点零模型正式推出之前,就已经把 cds 二点零深度用于多个春晚节目的视觉制作环节,所以春晚也是这款模型的第一个客户。
6.8万央视财经 01:41查看AI文稿AI文稿
01:41查看AI文稿AI文稿ai 视频毕业模板来了, emoji 二剧情故事版生成教学, emoji 二与 cds 二点零就是现在最强的 ai 安居版本。答案,你只需要把你已有的内容让 emoji 二去生成。像这样的剧情故事版包含分镜图,项目概述,故事基调以及视觉风格,还有 趣事节奏,还有风格参考。我整理了一份关于 emoji 二慢剧故事版的题词,感兴趣的朋友们我们评论区见,以此类推呢,你可以利用 emoji 二的能力去生成更多的分镜图或者是人物三式图以及分镜故事版。我们来看一下实际的生成效果就明白了。 知识改变命运,好好学习,将来走出山村,总有一天我会带着家人过上好日子。 可以看到我们这种情绪类的 ai 短片就是这么简单。那么我们可以发现啊, d 的 二点零十五秒的视频只需要六十八积分,跟其梦是相同的。积分消耗原理主要是因为我们选择的四八零 p 分 辨率以及二点零 fast 版本,但是生成效果大家肉眼可以看到。在这里我们还可以进行一个操作,就是画质增强,额外花五积分, 再把这段视频增强为一零八零 p 的 画质,包含现在的二点零 pro, happy house, sora, crook, vivo 度以及可灵,还有同一万像等等等等的模型,包括融合生图里面我们也可以看到 emoji 二, nasa banana 还有 mini 这些热门的大模型全都有。我们等一下让这个画质增强,看一看生成效果是怎样的, 根本就不用再去官网去花费大额的积分去生成十五秒视频了,可以看到我们的画质高清已经结束了,现在就是一零八零 p 所给大家展示到的效果,所以说想体验同款不砍人脸,同时能够做到低积分消耗生成 c n s 二点零的朋友们,关注私信我即可。
295Ai漫剧凌云 00:26查看AI文稿AI文稿
00:26查看AI文稿AI文稿c 档四二点零真的太可怕了,刚才我只是把我的漫画书拍了几页给他,他就给了我这样一段视频, 看到没有,不仅有配音分镜,就连 bgm 都给你加好了。唯一美中不足的是最后一帧弗丽萨他身上的伤痕累累的,这种状态没有表现出来,但是我不告诉你,你能看出来这是 ai 生成的动画吗?
7516茂茂说AI 02:59查看AI文稿AI文稿
02:59查看AI文稿AI文稿什么火遍全网的 cds 二点零竟然在剪映也可以用了?只需要一句话,你就可以把画面变成马年定制风格,或者 p 掉视频中的人, 还可以把自己变成这样,这样或者这样 用完之后,我就想问其他剪辑软件拿什么跟他打?我们直接在 app 中找到 ai 视频生成功能, 过年期间还限免。这里面已经内置了非常多好玩的模板,比如这个修改视频风格,点击做同款,将视频替换成自己的片段, 也可以根据自己的喜好修改为其他风格,点击生成,你就可以得到片头的效果。或者你可以随便找几张图,让你家的猫和图二的怪兽在图三的环境中大战科幻灾难。大片质感点击生成你就会得到 参考。视频动作当然也不在话下,从来生死都慢,但专和老天 对着干。还有这个视频删除功能,可以移除掉任何你不想要的元素,片头的人物移除便是用的这个功能, 如果你还想要深层的背景更加准确,也可以将空背景单独喂给他,这可比我们传统一层一层扣土的效率快了一百倍啊! 而这个效果则是用了修改视频主体的模板,只需要随便录一段视频,加上任意想替换的图片即可。除此之外,还有个很牛的用法引擎,奥福克影视级广告大片。我们就用这个手机举例,用一张图片加上简短的提示词,看看它能做出什么效果。 introducing the all new ultra premium smartphone 以上的举例其实都是非常基础的玩法,你也可以发挥自己的脑洞,或者用 ai 工具进一步生成更加强细的提示词,不管是商业片还是短视频和带货视频都可以用一样的思路。 不得不说现在的 ai 进化速度实在是太快了,去年还被嘲笑是人工智障,现在已经逼真到分不清真假了,谁也不知道未来会怎么发展。也许 可能真的不需要摄影师了,我们能做的就是不要抗拒 ai, 顺势而为。以后谁还敢说视频不能 p, 我 就。
8262李神仙z 27:15查看AI文稿AI文稿
27:15查看AI文稿AI文稿家人们,清华大学全套 ai 漫剧制作教程,全程干货,无废话,拿走不限警告!本视频耗时三个月制作,制作时长五百分钟,陪你系统学习 ai 漫剧制作,这应该是目前抖音最良知的 ai 漫剧教程了,哪怕你是零基础也能轻松学会。 所有教学过程中用到的指令提示词、模型安装包、分镜提示词都已整理完毕,评论三四五带走一份,兄弟们只要认真学完, 年底喜提法拉利!大家好,从这期视频开始,我们就来讲解像刚刚那样的 ai 动画短片是如何制作的。想要制作一个完整的 ai 动画短片,其实和常规的动画短片制作流程并无区别,只是得益于 ai 的 加持,很多工作都可以由一个人独立完成, 多专业的知识也可以借助 ai 快 速的进行学习和掌握。制作一个完整的 ai 动画短片主要分为这么几个流程,写故事剧本,写故事脚本。根据剧本和脚本生成图片,然后是根据图片来生成视频, 视频生成音效,生成人物配音,最后就是后期的剪辑制作,相信作为新手的同学看到这么多流程会感到有些头痛。不过不用担心,从今天开始,我们会从最基础的用 ai 大 语言模型编写故事剧本脚本,再到最后的剪辑 成片,从零开始,非常细致的教大家如何制作一个完整的 ai 动画。这期视频我们就先来讲解第一个部分,如何利用 ai 大 语言模型来编写故事的剧本脚本。同时我们这期视频相关的学习资料也放到了评论区的置顶评论,大家需要的话可以自取 们大多数人都不是专业的导演和编剧,因此想要获取好的故事剧本脚本,通常就要借助 ai 大 语言模型的生成,例如豆包、 deepsea 等等。这时如何给 ai 大 语言模型进行提问就显得非常重要。在给 ai 大 语言模型提问时,这里有一个通用格式,需要满足三个基本要素,第一点就是给 ai 设定身份,第二点是给 ai 提出问题,而第三点是给 ai 的 回答设定格式。我们首先来看第一点,给 ai 设定身份。来到豆包 ai, 可以 看到这里我一共向他提出了两个问题, 第一个问题是假设你是一个导演,请和大家科普一下什么是动态慢。此时他所给出的回复是动态慢的核心定义,动态慢的关键特征,以及动态慢与动画漫画的核心区别,且这些内容所给出的格式非常的专业。我们再来看第二个问题, 其实这里问题是一样的,同样是请和大家科普一下动态漫,但此时给 ai 设定的身份是,假设你是一个脱口秀演员,可以看到这里他所回复的内容就和刚刚有一定的差异,是以更加接地气且通俗易懂的方式来介绍动态漫的,例如什么懒人福音精简版, 连漫画的画稿不动给他俩加 buff。 同时将动态漫漫画和动画做了一个简单的对比,讲述的方式非常诙谐幽默且更加通俗易懂。这就是我们给 ai 设定的身份不同而产生的不同的结果, ai 会以不同的角度,不同的专业做出不同的回答。我们再来看第二点, 给 ai 提出问题,这里没有什么特殊的技巧,我们就直接简单直白的向 ai 提出我们的问题,就好比如这里的请和大家科普一下什么是动态漫,就是一个简单直白的问题,通 常向 ai 询问时,如果没有今天我们所讲解的提问框架,大家大概率也是这么提问的。而第三点,我们需要给 ai 的 回答来设定格式。例如现在我们可以看到当前的回答格式是大标题加小标题加内容的方式进行回答的,那么我们现在以第一个问题为基础,将其复制下来 粘贴。后面来追加一句,需要从内容基础、制作核心、技术、适配合规与传播这几个方面去分析。现在回车发送可以看到,此时豆包 ai 回复的内容就是围绕我们所提出的要求进行回复的。从内容基础, 以漫画 ip 为核心根基,制作核心、轻量化动态加生化适配技术适配适配多场景的轻量化技术,合规与传播、版权先行加精准破圈这么几个角度对问题进行的回答,这 就是给 ai 的 回答来设定格式。在向大语言模型提问时,相信大家使用这样的框架都能够获得较为理想的结果。我们下面就回归到本节课的主题, 如何让 ai 来编辑剧本脚本,这里我已经提前准备好了,我们来看一下具体的内容是怎样的。首先要明确一点, 剧本和脚本是不同的,可以看到在这里我分别生成了故事的剧本和脚本,在剧本方面,我们点击查看可以看到 更像是一则故事的直观叙述,就像阅读一本小说一样,没有非常的杂的解释,只是顺着观众的正常思路来讲述一则普通的故事。而脚本则不同,它的内容会更加繁复,包括了警别场景对于画面内容的描述、静号 以及发生的时间。它更像是一本在制作这个故事完整影视作品时的一个指导规划书,告诉我们在拍摄这一段时应该注意些什么, 该按照什么样的方式去制作。那么了解了故事剧本和脚本的区别,我们再回到刚刚的内容来看具体的提问方式是怎样的。可以看到这里同样满足了提问的三要素。首先第一点,给 ai 设定身份 是一个经验丰富的动画电影导演,这句话就给 ai 设定了一个经验丰富的动画电影导演的身份。下面是提要求,现在我需要你写一个动画电影短片的故事剧本。这句简短的话就提出了我们的要求,是写动画电影短片的故事剧本。而第三个部分就是 给回答来设定格式,要求是情节简单,故事有逻辑,以古风修炼为题材,以写故事的方式提供给我,以 便于我能快速了解故事内容不超过四百字。而在下面我们生成脚本的时候,可以看到就没有再给 ai 设定身份了, 因为通常来说 ai 大 语言模型是有关联上下文的能力的,我们在第一句话中已经给他设定了一个经验丰富的动画导演的身份,所以默认在后续的提问中,即便不再单独的设定身份,这个身份已经贯彻整个的对话了。那么到了这里,大家可能会产生一个疑 问,那就是既然我们生成的分镜头脚本能够直接告诉我们在真正制作短片时,该在什么位置,用什么样的描述,设定什么样的时间,为什么还需要先让 ai 生成一个故事的剧本呢? 其实道理很简单,作为一个导演,也就是我们自己,要想制作出完整的故事,就必须要先深入对故事有一个清晰的认识,知道故事当中的出场人物,故事的情节。 相较于永长的脚本而言,一则故事的剧本能够让作为导演的我们像阅读一个短片故事一样,快速的了解 整个故事都发生了什么,这样在制作时才能够更多的打磨这个故事的细节,了解故事的前后逻辑。其次,我们先行编写了一个故事剧本,也能够十分方便的对故事剧本当中逻辑不通或者不够精彩需要修改的部分进行提前修改, 在修改好之后,再让大语言模型参考修改后的内容来生成更加完善的脚本,以此来降低后续修改的成本。毕竟修改一个简短的剧本要比修改一个永 长的脚本要方便得多。在生成一个 ai 动画故事短片时,大家可以看到开头我们所展示的动画短片在时长上都不是很长, 通常一两分钟,所以这里生成的字数就非常重要。通常来说,四百字的故事剧本对应的是两分钟左右的 ai 动画短片, 所以大家可以以此为基础,在设定 ai 的 回答框架时,来设定一下生成的字数。此外,在生成脚本时,我们所要求的回答格式中,很多内容其实都是为将来生成图片而服, 所以大家在提要求时,尽可能想一想我们将来在生成图片时需要哪些信息。例如这里我的要求是要包括景别、场景、出场、事物造型、时间、提升画质的提示词描述。因为在生成图片时需 需要的便是对于这些内容的描述,同时还要求描述尽量直观客观,避免华丽的词造。这句话非常的重要,大家如果使用过一定的 ai 图片生成工具,你会发现在一些小说当中比较华丽的对于画面内容的描述,极有可能会误导 ai 图片生成模型。 例如在小说当中可能会描述长城蜿蜒的犹如一条巨龙,如果使用这样的提示词让 ai 图片生成模型生成图片,那极有可能生成的不在 是长城,而是一条真正的巨龙。所以我们才要求描述时尽量直观客观,避免华丽词造,以便于后续用于 ai 生成分镜头图 片。当然最后我们还需要补充一句,因为本身我们并非是专业的导演编剧,不知道一个脚本作为基础的要素都有哪些,所以最后补充了一句, 同时要具备脚本基本的要素,至少让这个脚本在满足我们要求的同时,它也是一个完整的脚本。我们最后来简单总结一下这期视频都讲解了哪些内容。 先我们大致讲述了制作一个 ai 动画作品完整的流程都有哪些,这也是我们后续课程当中会逐一给大家详细讲解的内容。而本节课我们讲解了如何编辑一个 ai 作品 的故事剧本脚本,其重点在于给 ai 大 语言模型提问题时的框架,分别是给 ai 设定身份、给 ai 提出问题以及给 ai 的 回答。设定格 是我们通过一个简单的苹果例子得知了这个框架的重要性,同时也在实践中生成了剧本脚本,并且对什么是剧本, 什么是脚本,他有,他们都有什么功能做了详细的区分。下一期视频,我们来学习如何根据生成好的剧本脚本来生成分镜头图片,这也是整个制作环节最花时间的部分,因为它不仅要生成图片,还包含了设计故事当中各种事物的形, 以及如何保持角色前后的一致性,如何对生成不满意的图片进行修改等等。在上一期视频中,我们使用 ai 大 语言模型生成了剧本和脚本,这期视频我们将利用已经生成好的剧本脚本来生成分镜头图片。 首先我们需要了解为什么要生成分镜头图片。在大多数时候,想要制作 ai 视频片段,我们都并非在 ai 视频平台以纹身视频的方式直接生成,因为本身生成一条 ai 视频在资金和时间成本上消耗不低, 使用纹身视频的方式有太多的随机性,极有可能生成十条视频,有五条都是不满意的结果。因此,在大多数情况下, 我们想要生成 ai 视频片段,采用的方式都是先生成图片,再使用图生视频的方式,以此来更加可控的生成视频片段。所以生成图片是制作 ai 视频作品必不可少的一环, 也是最花时间的一环。我们这节课会从前期准备提示词结构、提示词描述技巧以及图片修改技巧四个方面来讲解和分镜头图片生成相关的知识。 首先来看生成图片的前期准备,通常来说一则完整的故事都是需要故事当中出现主要人物或者说主要事物的,所以首先我们需要对故事当中的主要人物进行造型设计。 通常来说,在生成的脚本当中就会包含简单的对人物造型的描述,比如我们上节课对陌生的描述就是树发浅灰不一。因此如果甲方或者我们自己对生成的主要角色并没有特定的要求,可以直接在 在提示词中要求根据脚本生成陌生的全身正面角色造型比例是多少,风格是什么可以看到,此时我们就直接获取了关于角色造型上的一个设计。当然,除了根据脚本当中已有的简单描述对角色的造型进行设计之外,我们同样可以根据自身的想法 来单独设计角色的造型。比如人物没有束发,可能是披头散发的状态或者是短发。人物的服装不是灰色的,可能具有更加华丽的设计和其他的颜色。这些内容我们可以直接用正常描述的方式告诉 ai, 都是可以生成对应的结果的。再来看前期准备当中的第二点, 对故事画面的美术风格进行设计。要知道大多数的影视作品在美术风格上都要保持前后的一致性,不能说前期是写实风格,后期就突然变成了三 d 风格。所以这里我们也要预先对将来画面当中的美术风格 进行固定,这里同样是要通过提示词来描述,比如这里在生成角色造型时,我的要求就是高精度三 d 建模风格, 此时生成的角色就不像写实人物那般有着写实的比例和长相特征,而是更像是一个三 d 动画电影当中的人物长相。那么问题来了,如果我们喜欢某一张图片当中的美术风格,但又不知道该如何用提示词描述, 该如何获取这个风格的提示词呢?其实方法也非常简单,比如现在我们来到极梦 ai 的 首页,在这里可以看到很多由其他作者生成的作品,如果喜欢当中的某一个作品的美术风格,我们就可以点击查看大图。 以这张图片为例,可以看到右侧就展示了作者在生成这张图片时所使用的提示词,而我们要做的事情就是直接将这些提示词复制下来,在复制好之后, 回到豆包 ai 当中,直接 ctrl 加 v 粘贴,然后按住 shift 键再按下回车另起一行,此时向豆包 ai 这个大语言模型提出要求,去除上述提示词中对具体事物和氛围的描述,只保留画面美术风格相关的提示词, 然后点击发送可以看到,这样一来,我们就快速的从其他作者的作品当中提取出了和美术风格相关的提示词。 当然由 ai 提取的和风格相关的提示词未必都是准确或者说我们需要的,所以在使用时还需要经过一次人工的筛选。 比方说当前所提取的这些提示词中,像全景航拍就并非是对美术风格的描述,而是对景别的描述,在使用时最好先将其删除,我们下面就对刚刚所提取的提示词进行一定的删减, 同时配合自己新增的提示词,描述一个古风帅哥在御剑飞行近景特写这样的提示词来生成一组图片,看一看效果如何呗。可以看到最终生成的效果在美术风格上是不是和刚刚我们所见到的那种带有三 d 质感的图片非常的接近呢?当然在很多时候使用这样的方法 与生成的主题不同,在美术风格的最终表现上也并非绝对能够完全贴合我们参考时作者生成的图片。大家可以多对提示词的描述,根据自己的理解,结合生成的结果进行修改,以此来满足自己对画面风格的要求。 回到豆包 ai, 我 们继续来承接之前的内容,在设定好角色也就是陌生的形象之后,我们自然要继续设计画面当中出现镜头比较多的 零露的形象。这里我们就继续向豆包 ai 要求用相同的风格生成脚本当中提到的零露,可以看到最终生成的效果也非常出色,成功的生成了零露的形象。当然大家同样可以靠自己的想象来描述零露都有什么样的特征。我们现在已经获取了人物造型的设计, 同时也规定了画面的美术风格。下面要做的事情就是书写提示词,描述来生成脚本当中的每一个分镜头了。主要有这六个方面, 分别是景别,比如近景、中景、远景等等。第二个方面是画面当中出现的事物,像人物、动物、环境等等,都是画面当中出现的事物。而第三点是时间和光照,白天、夜晚、傍晚的光照是 不同的,同时光照也可以来自于不同的方向,像正面光、侧逆光等等,能够表达的人物情绪也有区别。 色调方面包括冷色调、暖色调,或者可以用某一部电影当中的调色,比如教父的风格等等。而构图方面则包括水平构图、对称构图、 s 型构图等等,可以让生成的画面体现更多的情绪。最后一点是质量词, 像胶片、颗粒、质感、电影感构图、超高清、十六 k 等等,这些词汇都能提升生成结果的画面质量。例如在设计好陌生和零露的形象之后,我们就开始了第一张图片的生成。这张图片就集合了刚刚 所说的提示词结构相关要素。景别方面要求是航拍镜头、远景,而这里的白天、晴天则是在描述画面当中出现的事物。 像胶片、颗粒、质感、电影感构图、超高清、十六 k、 三 d 高精度建模则是带描述画面的美术风格 以及相关的质量词。可以看到,在这些描述当中,我们并没有描述色调,这里主要是从两个方面考量的。第一个方面,本身 ai 生成的图片在色调上表现的就足够优秀了, 不需要去单独的提及或者调色,即便要调色,也可以用后期的剪辑软件,以更加可控的方式进行调色。第二方面就是我们在生成图片时 刚刚所提及的各种提示词结构,并不是每一种都要在生成图片时使用,比如说景别,有时候我们不去描述,但要求生成的内容是人物的证件照,通常也会采取近景取景框、指框选人物上半身的方式来生成人物的证件照。 所以在很多情况下,我们就主观的描述自己想要生成的画面,无需考虑刚刚我们所讲解的提示词结构也是能够生成很好的效果的。当然,如果生成的质量不佳,我们自然还是要根据刚刚的提示词结构来了解如何去完善当前所书写的提示词,生成更加令人满意的效果。 下面再来看生成图片时的提示词描述技巧。首先第一点,提示词描述尽量直观、客观,和写作文、写小说是不同的。在生成图片时,太多的修饰词可能会导致 ai 误判我们的意图。比方说我们上一节课所展示的说长城蜿蜒的像一条巨龙, 我们的目的并非是要生成巨龙,而是在描述长城本身这个建筑的宏伟景观。但很多时候 ai 是 不会了解这样的华丽的词造的。类似的描述还有鲫鱼跃出水面飞得很高,就像是长了翅膀一样。 用这样的描述来生成图片,也极有可能会让 ai 认为我们要生成长了翅膀的鲤鱼,而并非在描述鲤鱼飞的很高。可以看到此时生成的结果就当真生成了一条长了翅膀的鲤鱼。因此在描述时要保持直观和客观。第二个技巧, 脚本只是参考画面描述,主要还是要靠自己思考。在很多的 ai 视频生成教程当中,会有一些教程会教大家直接复制粘贴脚本当中的提示词来生成分镜头画面。但事实上,在这些分镜头画面的描述中,会存在很多不合理 或者不适合在同一个镜头下生成的内容。例如我们看第一个镜头陌生有什么样的造型,青石有什么样的造型, 同时还描述了陌生身上戴的这块玉玑是长方形的,有淡白玉色,有简单纹路。但实际上我们都知道,在一个人物的全身,也就是打坐的画面中,人物身上所携带的这块玉玑是基本不可能看清上面有什么样的纹路, 甚至看不清它具体是什么形状的,因为在整个画面当中的占比可能非常的小,所以像这样的画面我们就无法在同一个脚本分镜头中生成, 而是至少需要分为两个画面,一个画面是陌生在打坐的画面,另一个画面才是预觉得近景镜头特写,如果直接复制粘贴这里的提示词生成的画面就会非常的矛盾。所以大家作为导演, 在拿到剧本脚本之后,最好能够先在自己的脑海中形成一个完整的画面,在更多的时候,我们根据自己脑海中所形成的完整画面进行提示词的直观客观描述,这样往往能够生成更好的效果。而第三点就是 ai 目前能力有限, 有时需要适当的修改提示词描述的内容,或者在生成好内容之后,我们对剧本和脚本进行一定的更改。举一个简单的例子,例如像当前故事剧本当中的第一句话,他猛的睁眼,将手中的欲绝置在青石上, 欲绝滚落进西间。如果大家有一定的 ai 视频生成经验的话,会发现这一句话当中所描述的人物动作,在 ai 视频片段的生成中其实非常难制作,人物需要先将手中的欲绝抛出,欲绝需要掉落在青石上, 同时在青石上还要进行滚落,滚落到西间见其涟漪。如果是真实拍摄视频,这串动作并不难做到。但实际上在 ai 生成时,这种涉及到诸多物理碰撞的内容,想要制作成功是一件十分困难的事情。 所以这里我们不妨直接让玉玑丢进水中,同样能够表现人物打坐三日无法引气入体,内心烦躁的情形。 当然,在遇到类似的情况时,可以先尝试按照剧本当中可能更复杂,但表现力也更好的画面去生成,如果做不出来的话,再考虑改为更加简单的画面。第四个提示词描述技巧,就是有角色说台词的画面时,尽量使用近景正面镜头, 这同样是我们将来在给角色对口型时,能否成功的给角色对口型进行考量的。在极梦 ai 当中,给角色对口型使用的是数字人功能,它需要我们先上传一段视频或者图片, 添加对应的配音。当我们需要对口型的人物是一个远景人物,且并非正面朝向镜头时,此时对口型要么会失败,要么效果非常不明显。比如说我们来看这段视频,孤独 使我的内心更加坚强。可以看到,虽说生成的画面人物的嘴部依然是有动态的,但整体的表现效果会相对一般,人物的身体也伴随着说话出现了不太自然的动态效果。我们再来看一个人物近景特写对口型时的画面,咕咚 使我的内心更加坚强,可以看到此时生成的画面,人物的口型和台词就十分匹配,且面部的动态表现比较清晰自然。所以当我们遇到有角色在说台词的画面时,就尽量使用近景和正面的镜头,以获取更好的对口型效果。我们最后来看图片生成之后的修改技巧。 在通过纹身图生成图片时,很多情况下并不能一次性就生成让人满意的效果,但也许生成的图片百分之八十是满意的,剩余的百分之二十相比于重新生成一张进行后期的修改是性价比更高的选择。 有些时候我们需要表达一个很长的镜头,以此来表现画面的时间流逝或者是人物的一连串动作。所以我们首先来看第一点,固定镜头下长时间事物运动的表达技巧。这里就包含很多方面了,比如我们现在想要表达一年四季的变化, 那么在生成好人物盘腿打坐的画面之后,我们就可以直接让 ai 大 语言模型帮助我们固定画面当中的人物造型和构图,但只改变画面当中的四季。 比如我们首先生成的第一张图片是类似于春季或者夏季,在提示词中,我们要求将上图的季节改为秋季风格,其他部分保 持不变,此时就获取了人物在秋天打坐的画面。同样的道理,我们继续描述,将上图的季节改为冬季,其他部分保持不变,那么最终就成功的将图片 改为了冬天的季节。有了这些图片之后,我们使用首尾针生成或者多针生成的方式,就可以生成一组 人物,从春天到夏天再到秋冬天,一直在这个位置打坐,以此来表现人物十分勤勉、十分有毅力的镜头片段效果。当然,除了描述季节之外,我们也可以描述将人物修改成某种姿势,在人物的身边添加某些事物,减少某些事物, 其他部分保持不变,相信大家这里都能举一反三,我们就不再赘述。第二个图片修改技巧,就是如何在保持造型和风格一致的条件下修改环境和状态的技巧。其实这一点在大多数情况下不需要我们特意去保持, 因为使用 ai 大 语言模型来生成图片是有上下文关联的功能的。比方说我们在刚刚演示时,提示词中只描述了鲤鱼跃出水面,飞的很高,就像是长了翅膀一样, 本身的意图是想单独生成一条跃出水面的鲤鱼,但得益于 ai 大 语言模型能够关联上下文的能力,他依旧认为我是想要基于上面这张图片来修改新的内容,而且可以看到生成的结果在美术风格上同 同样保持了上图当中的风格,所以很多情况下我们不太需要单独的提及要保持画面的风格。但需要注意的是,在实际的制作过程中,偶尔会出现我们上传了一张参考图,但生成的结果和参考图在造型上美术风格不统一的情况。 就像这里是我之前制作了一个 ai 故事短片,在制作的时候,像这张图片是一个已经制作好的角色造型,是一个三 d q 版卡通形象,但人物整体还是偏向于写实的特征。在上传了这个参考图,提出了相应的修改要求之后,可以看到生成的结果并不能让人满意。 虽说人物在造型的设计上保持了一致,但整个人物的比例和特点都发生了翻天覆地的变化。因此在遇到这种情况时,该怎么解决呢?最好就要更换一个图片生成平台。在使用不同的图片生成平台生成图片时,其实每一家所使用的生成模型都会有所区别, 那有些模型擅长生成写实的风格,有些模型擅长生成绘画的风格,有些模型这个角度生成不好,有些模型这个风格生成不好,这些都是很常见的情况,所以大家在对图片的内容进行修改时,也不要在一棵树上吊死。 如果时代生成不好,除了用极梦 ai 或者豆包平台之外,也不妨尝试用其他的平台,比如说用可灵 ai, 或者像一些开源的使用 context 的 模型、 flex 模型或者 banana 模型的工作流都是可以的。例如现在来到利布利布 ai, 我 们点击这里的在 comfui 运行, 此时就来到了 comfui 工作流的操作页面。这是一个 context 的 模型的工作流,其基本功能就是参考图生图。在左侧的图像输入窗口, 将刚刚未能在豆包上生成成功的人物造型进行上传,在提示词描述当中描述我们的需求,例如这里我们就输入和在豆包上一样的提示词,根据图片生成人物特写,生气,拍桌子、表情愤怒。而比例方面,我们修改为十六比九,然后直接点击开始升图, 看到一段时间后,图片就生成好了,整体的生成效果还是非常出色的。我们将在豆包上面生成的人物造型放在旁边,同时将原版的人物造型参考也放在旁边。 可以看到在对比之下,显然使用 context 的 模型工作流能够生成人物的造型更加统一的画面效果。当然,在豆包上大多数情况下是直接可以修改的,只是偶尔会出现这样的问题, 对界时也不妨尝试使用其他方式,在保持人物造型和美术风格的情况下,来修改环境和画面当中事物的状态。最后一点就是灵活的使用参考图生图的功能。要知道参考图生图不光只局限于上传单一的图像参考,目前大部分的图像生成平台都是支持多图参考的。 比如现在我们将陌生的人物形象和零度的人物形象同时上传,在上传好之后,输入提示词,生成人物骑着白鹿在丛林中的画面,然后点击发送,可以看到最终生成的效果。既保留了零度的形象,也保留了陌生的形象,同时也符合了提示词中 描述的人物在丛林中的画面的要求。在很多其他的事物无法生成出来或者生成的结果不符合要求时, 同样可以使用多图参考功能,将指定的物品按照提示词的要求进行结合,灵活的使用参考图升图的能力。最后来简单总结一下这节课我们讲解了图片生成的相关知识,包括前期准备、提示词结构、 提示词描述技巧和图片修改技巧,这些知识能够帮助大家在生成分镜头图片时,更容易生成出理想的画面。当然大家在实际操作时遇到任何的问题也非常欢迎在评论区留言, 会尽可能帮助大家解决在操作过程当中遇到的问题。以上就是本期视频的全部内容,我们就下期视频再见。
256AI视频教学

猜你喜欢
- 237野渡