线性回归r值计算公式
同学你好,我们来看这道题为打造四泰融合、产村一体,望山见水一乡愁的美丽乡村,增加农民收入。某乡政,某乡政府统计了景区农家乐在二零一二到二零一八年 任选五年接待游客数 y 啊,他的数据如表格。 第一问,让我们根据数据来说明 x 和 y 是正相关还是副相关?这道题考察的知识点, 第一个是这个正相关还是副相关的概念, 其实简单来说就是正相关,就是单调递增啊,副相关就单调递减, 爷爷说随这个 x 这个年号的增长,这个数据呢,是变大还是变小?如果变大,那就是正相关,如果变小呢就是负相关,那看 二三五七八,这个 s 增大,三三点五四六点五八,那很显然这个随着 s 增大外也增大,那么应该是正相关的。所以第一问比较简单, 随着 随着 x 增大 啊,歪也从他 啊,所以呢是正相关,所以 y 与 x 正相关。 第二问,让我们求这个相关系数啊,给出了相关系数的公式。然后呢,说明这个相关系数 和这个年份,和这个游客到底是相关性强还是弱,那么认为这个相关系数大于零点七五的时候,那么具有较强的很强的线性相关关系, 那其实就是求这个公式啊。这公式当中,我们看 xi 和 y 在一个表格当中都有了,那就是还差一个 x 八,还有 y 把这俩量是什么关系?也就是 x 的平均数以及 y 的平均数。所以呢,这个第二问,我们应该首先求这两个平均数, 那么应该是一二三四五五个年份,那就五分之二加三加五加七,再加上一个八 啊,这个值应该是五歪把 五分之三加三点五,再加上一个四,再加上一个六点五,再加上一个八,这个值应该是啊,也是五, 这样呢,两个平均值求完了,可以带入这个数据了啊,我们直接计算一下,这个 r 应该是 从一到五 xi 减掉五乘以 y 减五 字母是根号下一到五 x 减掉五 啊,他的平方啊,其实呢也可以写在同一个根号下,里面 按从一到外 减五的平方 啊,就是上面这个数据,上面这个分子就是 x, 每个数都减五,然后呢 yy 每个数也减的这个平均数五两个相乘,然后呢把这五个加在一起,下面这个呢是减完五,然后呢首先平方,比如说二减五平方, 三点五平方,这俩平方相加啊,五减五平方,七点五平方,八减五平方,这些所有的平方加在一起是这一部分,那么下一边这一部分呢,就是啊,所有的这个 y 指也减掉五,然后呢 每减一个平方平方,这个然后再加盒啊,计算这么两个值,把这些所有的 xi 以及 vi 代入,那么可以得到这个分子是二十一分母呢,应该是根号下二十六乘以根号下十八点五,那么这个值经过计算应该是零点九五八, 零点九五八,他是大约零点七五的,那说明相关性很强, 相关性很强。 我们或者说完整的回答,这个年份与游客数, 游客树木 年份与游客数,相关性很强。 那么总结一下考察的主要的知识点,第一个我们要知道正负相关的概念啊,看这个随着 x 增大,这个 y 值怎么变化?如果随着 s 增大, y 也增大,那是正相关,反过来呢?就是负相关。第二问,求这个先人相关系数,应该首先把这个 x 八 y 八计算出来 啊,就是 x 平行数以及 y 的平行数,计算出来之后带入到这个先人相关性的公式就可以了。 那么大于零点七五就是相关性很强,那么计算出来零点九五八,说明这个相关性的确非常强。那么好,这道题就讲到这里,再见。

粉丝1747获赞1.9万
相关视频
 03:43查看AI文稿AI文稿
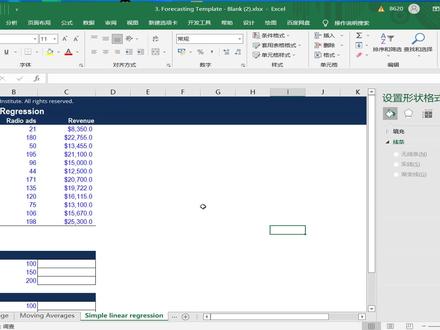
03:43查看AI文稿AI文稿哈喽,大家好,我今天给大家讲一下线性回归,用 xl 怎样能做出一个线性回归的函数,我们用这个例子,那我们现在就是看一下就是广告收入和他这个营业输入他们到底之间有什么关系?我们大家就看一下他是成正比,那我们具体的用数据表现出来,首先我们 选择这两页数据,然后我们再找到插入,插入以后我们再找到散点头,我们找到散点头以后,那我们把这些线删掉,让我们头清清晰一些,然后我们这个点,嗯, 我们添加上趋势线,我们就把他的趋势线添加出来了,我们看着趋势线,他是点状的,那我们把它改一下,同学改,把它改成 线型的,实心的,把改成实心的颜色,我们改成深蓝色,好看一些,然后我们再加上他的那什么显示公式,然后再显示 r 平方, x 是我们的广告,应该说是 y, 所以就是说这两类数据做出了回归方程式,也就是 y 等于一七十八点零五 零 t 五点 x, 加上七千九百三十点四,然后 r 二平方, r 平方代表的是呃,百分之九十三点二七的 y 可以被 x 解释,那我们就把点赞先人回购就做出来了, 那我们可以验证一下我们这个方法到底对不对,就可以用 forcass 函数,嗯,对了,我这里说一下,这一百我们代表是广告 x, 那我们用 forcass 函数, 然后我们输入 x 值,这里就代表广告,然后你看他需要第一个是 knowing why, 那就是营业收入,然后还有 knowing x 他的广告, 然后我们就可以看下,在广告投入一百的情况下,他有一一万五千七百三十七的呃营业收入,那我们看一下一百五十,那我们呃就直接复制公式吧。我们要做的就是先把这个 c 四到 c 十五固定一下, 当然你可以直接按住 f 四,因为我现在录屏没办法按 f 四,他是没有作用的,我只能一个一个的美颜符号一个一个打。 ok, 然后我们回车一下,然后我们 ctrl 加 c, 然后我们再 ctrl 加微,我们就看一下,如果广告是一百五,营业收入就是一万九千六百四十一,如果广告是两百,那我们的营业收入是两万三千五百四十五点四, 那我们可以用我们就是我们刚才回顾的方程式来验证一下福克斯的函数,那我们一样的就是七十八点七五,也就是他的斜率乘以一个一百,再加上他的拮据,提前九百三十点三五。 嗯,那我们一样的最好在这里,因为下面还有两个数据吗?那我们需要在这打上美颜符号,方便我们对公式的复制下。广告是一百的情况下,和上面我们用 focars 函数算出来的那个值是一样的,然后我们 ctrl 加 c, 然后我们 ctrl 加微,那我们如果是广告投入是一百五十,那我们的收入是一九六四一点六,和我们 freecast 函数算出来是一样的两百同里。那好了,我们今天就到这里,如果大家有什么问题可以给我留言,然后我会尽量给大家解决的。行,谢谢大家,再见。
447一起学法语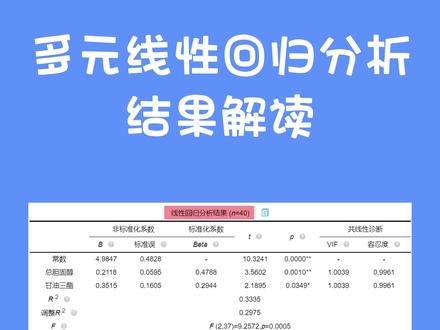 00:50查看AI文稿AI文稿
00:50查看AI文稿AI文稿多元线性回归分析结果解读,一、模型拟核优度二方,比如二方为零点三,则说明所有 x 可以解释外百分之三十的变化原因。二、共限性判断通过 wave 或者容忍度判断自变量之间是否存在共限性,容忍度等于 e, wave 值 值大于五,说明有贡献性问题。三、自变量显著性查看 x 对应 t 检验的 p 值, p 值小于零点零五则说明 x 对 y 有显著影响。四、写回归模型公式,构造公式使用非标准化回归系数。五、对比分析 x 对 y 的影响大小, 使用标准化回归系数也可以直接参考 specs 智能分析与分析建议进行结果解读,你学会了吗?
751SPSSAU 01:15
01:15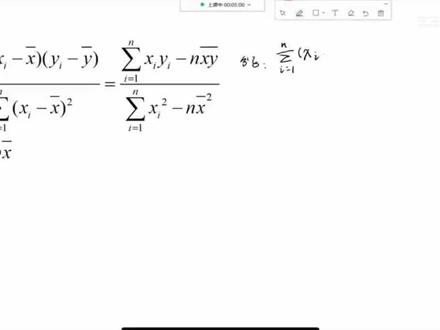 15:00
15:00 10:16查看AI文稿AI文稿
10:16查看AI文稿AI文稿下面我们开始讲今天第三部分啊,也就是这个决定系数,我们会介绍一些定义啊,包括残叉理解是变量,问题是变量。然后呢再去讲一个怎么去评价模型好不好?一个量叫做玩方。 首先定义我们如何去评价我们这个拟合的效果呢?就是用这个残插 e 是可以去做这个事情的,要么观察值和拟合值的差,就是我们这个残插 e, 也就是等于 y 减去 y 的这个估计值,不要 vi 减去 y 的估计值 等于 y 减去外半减去这个外估计减去外半,对吧?如果我们把这右边的 括号去掉,我们就发现这个外半消掉了,也就是 y 减去外估计时这样子,所以我们可以把上面这个式子改写成这底下这个样子,对吧?我们把这一下移到左边去,我们把它移到左边去。 紧接着我们把这个我们得到的式子,再利用平方求和的方法,我们是可以得到底下的这样一个式子,对吧?就是左边这个东西是 ya 减去 ybug 平方的一个 summation, 右边分别是外孤寂减去 ybug 和 y i 减去 y 估计的这样一个平方值,并且把它们三倍胜分别三倍胜起来,我们得到这样一个式子,这个式的第一项就左边这一项,我们把它叫做总平方和 sst, 右边第一项我们把它叫做回归平方和 ssr, 右边第二项我们把它叫做误差平方和 sse, 对,就是这样一个式子。因此呢我们就知道了, sst 等于 ss 孩加上 sst, 其实也就是我们自己定义的这样一个量,对吧?这样一个东西, ssr 也称为已解释变量,就是我们已经可以去解释到这样一些变量,但是 ss 艺术没有办法去解释一些变量,解决到未解释变量, 为什么呢?因为 ssr 其实是什么呀?其实是我们估计出来的是和外这样一个君子之间的差,对外估计是我们有一些, 就是里,呃,就有一些道理,对吧?有一些东西,我们比如说用 x 根据一些就做了一个现象回归,所以我们是用 x 去导出来这样一个外,或者说 x 去 猜估计出来这样一个 y, 对吧?所以说我们 y 是有,呃,这个 y 是有依据的,对吧?这个 y 估计是有依据的,但是这个 y i, 对吧?直接去点 去这个外估计,这个这个东西我没有办法去解释的这样一个差距,我没有办法知道为什么这个外值和这个外的估计值之间是有差的,对吧?也就是说这个残渣哪来的呢?然后不知道的这里说到这里多讲点东西啊,就关于残渣这个事情。 残渣这个事情呢,就是说我们实际上如果我们的模型包含的数据足够广泛,足够多的话,按理来说我们的残渣会越来越小,或者说如果他有的话,他也应该是遵循一个正态分布的。 但是如果我们这样一个那个什么,就是我们这个数据,比如说我们的这个数据级比较少,因为我们现在说的是一元的现象回归吗?如果我们到到时候是多元的现象回归可能会好一些。一元的话,我们只用一个 x 去估计一个 y 表带时间外 是跟更多的因素有关的,就比如说我们刚刚之前说到那个,呃,就是田地里面这样一个施肥量的情况,对啊,施肥量越大,确实,那我们可能是怎么样呢?我们可能说是我们这个庄稼, 这个叫做收成更好,但同时也跟土壤啊乱七八糟这些东西都是有关的。所以如果我们有既有天气,又有那个土壤的条件,又有湿度的一些东西,又有 有这个施肥量,各种变量我们都有的话,做出来这个回归可能比较好的,那么这个残渣就更像一个正态分布。但如果我们只用一个变量,比如说我们只用这样一个施肥量的话,那我们的残渣可能就不太符合正态分布的样子, 对吧?就是因为我们把不知道的量,我们一无所知的东西,我们都全都扔到了这个残渣里面,就是残渣,就像一个垃圾桶一样,对吧?装着我们这些不清 清楚的东西放在里面去。当然这样一个思路啊,就是在这里多说两句。所以说我们说完了 ssrsse 这个这个东西之后,我们对上面这个公式,两侧同时除以这个东西,也就是左边这个东西,对吧?那左边这个东西就等于一楼把它移到右边去, 右边这两个东西就是底下多了一个分母,对,多了一个分母,这样子,也就是 s s r 出 s s t, 再加上 s s e 出来 s s t 等于一,对吧。这个时候如果我们定义 r 方,也就是可以解释的这样一个误差,占总误差这样一个比例, 对吧?这个比例的极限值是一,也是当 r 方越接近一的时候,你喝的效果就越好,对,你喝的效果就越好。 r 方是等于什么呢? s s r 除以 sst 等于一减去 sst 除以 sst, 比如这一项,对吧?也就这一项,我们把这一项给它展开来了,对吧?这一项给它展开来了,就等于一减去,就连这个把它也展开来,对吧?这样的一个事情, 或者呢,我们也可以把二方形右边这个形式,这个形式我们一般好去就如果真的要手算的话,好去手算一个形式,就是贝塔零呈上所有这个 y 加起来,再加上贝塔一乘上,呃呃,把所有的这个 xi 吧加起来,再减去 n 外方 就外八的平方,再除以 c 格外什么呢?外埃所有的平方加起来,再减去 n 本的外八的平方, 这个是我们计算二方的这样一个方式,二方这样一个方式,二方这里的话还是多说两句,就是说如果我们自己的数据级比较大的话,比如说十万个数据,甚至更多,对吧?这样一个数据,二方如果真实数据值你们跑出来大,哎,就如果你们有软件跑车大于零点六或者大于零点七, 对吧?就是一个比较好的值了,比较好的值了,如果没有大于的话,那我们也需要去做更多的事情,让这个值更大。当然如果我们数据级越小,那么二方的这个要求就可能更小一些了,对,这个就看情况了 这样子,所以一般的话,我们看到这个实际模型,如果他就有零点七,零点八,那就说明这个模型已经比较好了,但已经比较好能去体现出我们这个总体这样一个情况,下面我们开始今天的第四部分,第四 四部分是我们这个练习题,我们会讲一个关于先进回归的这样一个练习题啊,而且再去拓展一下关于这个在软件中一些应用学员练习题,如果知道这个,呃, c m x y 等于二百七十三, c 个 m x 等于三十二, c 个 m x 等于四十, c 个 m x 方等于二百七十四, x bar 和 y bar 分别等于三分之十六和三分之二十。我们想要去算这个回归方程,对吧?这是什么这样一个题?选书,如果我们想要去算他的话呢?我们就去找到之前的关于这个贝塔零和贝塔一的这样一个公式,对吧?在这里 贝塔零等于呃贝塔一等于右边这个东西,对吧? c g m x i 减去 n 贝的 x 八 y 八,贝塔零就等于 y 八减去贝塔一贝的 x 八,对吧?这样 样子,所以说我们在这里带回来,对吧?带住,但是这个相应的这个值之后呢?要 n 成上这个 s 八,这样子我们带到,带入所有相应的值之后呢,我们就得到了关于这个备胎一和备胎二,备胎一和备胎二,也就是我们就可以直接写出我们的回归方程了。外等于什么?什么东西 这样一个式子,得到这个式子之后呢,我们也可以算我们刚刚所说的这个 r 方了,对吧?这个 r 方也就是贝塔零乘上 c 管 y i, 对吧?再加上贝塔一乘上 c 管 x i y i 减去 n y 嗯,外八方,对吧?然后除以 y i 的平方的 c 个码,减去 n y 八的平方, 也就是这个东西,对吧?我们计算出来了,计算出来可以知道 r 方等于零点八七七这样的一个值,但是这样计算其实是非常麻烦的,即使我们给了这样一个元数,就 我们去做这个形式非常麻烦的。当然我们实际上是可以用各种软件去做这样一个快速计算的,包括像什么 spots 啊, status, 劳斯莱斯,还有这个 excel 这些东西都是可以进行进行回归的这样一个计算的,就如果你会编程的话,其实可以非常容易的去用程序去实现, 对吧?有的是你可以去输入你的 y 和 x, 他会告诉你就是相关的参数,然后呢,你也可以加上相应的这样一行代码或者一个东西, 让他帮你把这条线,你这条回归线也画出来,同时你可以把这个线画到这个呃,散点图上,对吧?你也可以画到就是一个空白的图上,都是可以的,对吧?这个就看自己的 想要,可就是让这个数据可视化的这样一个需求了,对吧?这个就看自己的一些爱好了。当然这个东西的话,我们 总是就是如果可以的话,当然是希望或者说需要大家去学一些关于这个 统计软件或者说编程语言都是 ok 的具体一些内容,因为统计软件的话,其实可以帮助大家更好的去更快的去做到更好的,就是更更得到更多的这样一个结果,对吧?并且更准确的一个结果。 然后如果大家选用编程软件的话,就可能是更接近一点要求了,因为编程软件的话会更好的去做这些事情,是因为说编程语言是比统计软件更加底层的一种语言,所以越底层的东西我们可以自己去实现一些更快的算法, 所以不是一个封闭的这样一个算法,所以我可能会说,呃,做起来的话更快一些。讲一个事情,这样拍分为什么这么厉害呢?其实就是因为拍分这个语言是非常底层的一种语言。 但是像啊买起来吧这种东西他跑起来可能就会慢一点,因为他是一个高度封闭的一个东西,这样子,对,这是我们今天说的这些啊,关于统计学的这个第第四节课,对吧?的一些内容。
122盐趣ViaX科研教育 02:02查看AI文稿AI文稿
02:02查看AI文稿AI文稿大家好,今天分享的技巧是用 excel 制作回归分析,或者说是你和分析。 举个例子,左边我们现在有一个数据员,然后有 x 和 y 轴的数据,我们现在要得到他的一个分析,他的一个规律,那么用 excel 得出他的一个你和的一个曲线方程,比如这里是一个对数方程,这应该怎么做 好?我们先把做好的进行删除,首先我们选中所有的数据,然后点击插入选择闪点图,好,我们选择这个闪点图,那么我们可以把图表标题进行删除,然后我们选中这个数据区域进行双击,然后在 右边的话就可以有他的一个标记,然后在标记选项里面可以改成类似,然后把标记点给他调小,然后我们可以在添加图标元素这里面选择添加趋势线 好,然后趋势线的话可以添加不同的种类,有线性的指数的或者等等的,比如我们现在随便添加一个线性的 好,添加完了之后,我们在右边可以选择我们的趋势线,我们点击趋势线选项,然后这里会有几种趋势线的一个选项,那我们看一下,我们这个是对数的,所以我们选择对数, 然后在底下的话可以显示公式以及显示啊平方值。如果说我们这个线条呈现一个线性的话,我们可以选择线性的,那么线性方程也会给 你列出来是多少,当然如果是指数的话,他也会列出来这个是最符合指数的一个方程是多少, 然后我们可以根据这个方程输入一个我们想要的 x 值,就可以得出一个预测的 y 值。好,关于这个小技巧,你学会了吗?喜欢我视频就点个赞,有什么不懂的欢迎在视频下方留言,我们下节再见。
9756Excel技巧 02:51
02:51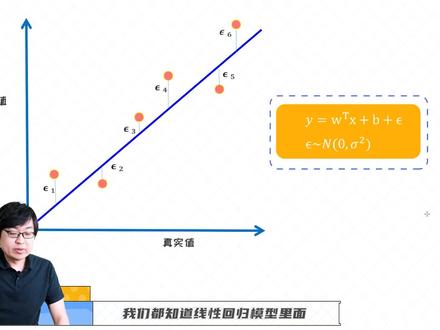 05:12查看AI文稿AI文稿
05:12查看AI文稿AI文稿我们都知道线型回归模型里面,其实他的目标函数呢,是平方误差,所以核心是这里的一个误差的概念。所以假如呢,我们给定了几个数,几个样本,然后呢,我们学出了一条线,那这条线的方程呢?其实我们知道可以用 w x 加 b 的方式来表示的,那这里的假设呢?就是啊,假设 x 它是一个多一个多维项链,也就是特征个数为更多的时候,我们可以用项链化的方式来表示。 但是呢,我学完一个一条线之后,其实每个样本他可能会有一些误差的, 那误差呢,我们分别用 f 三六一到 f 三六六来表示,然后这里面我们仔细来想一想,假设我把每个误差呢,把它想象想作为一个 变量,然后我假设这里面我只有六个六个样本,因为为了方便,期间我只只花了六个样本,但是假如呢,我们手里面有大概有一万个样本,或者是更多,所以我手里可能有啊,可能大概有一万个,或者甚至更多的一个误差的一个变量。 所以当我把这些误差变量把它合在一起的时候,我们是不是可以联想到一个非常重要的一个性质,就是叫做中心极限定理, 英文叫 central limiter, 什么意思呢?所以假,假如我手里面有非常多的样本,假设有一万个或者上,甚至呃,几十万个,那我手里面其实有这么多的误差变量,然后呢,英文我的个数已经很多了,所以 根据中心极限定理的哈,我们可以得到这些误差的变量呢,他可以服从一个正态分布,那这个就是一个非常非常著名的一个极限定理,然后根据这个极限定理呢,我们可以模拟出就是这么多的误差, 在这里叫做 fcelong, 那 fcelong 的误差呢?当他很多的时候,样本个数比较多的时候,他会服从一个正态分布,也就是这里的 f solo, 他会服从一个这种正态分布的形式,那这一点非常的重要。然后我们从这个点出发, 接着从一个概率统计的方式来去引导引引出我们最终的目标函数,所以这是另外一种方式。我们之前的方法呢,是直接通过 f 三网来去引出咱们最终的目标函数的,就是平方误差的 啊那块。但现在呢,我们从另外一个角度想去引出我们同样的目标函数,但这个方法论呢,更偏向于使用这种概率统计,包括一些把一些分布,把它用起来。所以在现阶段我们要记住的一点是,当我们学了一个 一条线,然后呢即便我学出一个很准确的一条线,我们每个点其实他会有一个误差的,就是对于每个样本来讲,他有一个误差, 但是呢这个误差比较比说很大的时候,也就说我的样本个数很大的时候,那这些所有的误差, 根据中心极限定理,他会服从一个正态分布,所以啊,这点很重要。 那下面我们具体来写一下刚才我们所说的误差模型。 所以呢,我们现在学了一个方程,叫 w 和 b 两个参数,然后这是我的预测值,左边是我的预测值, 然后我加了一个误差,叫 f 送一,那对于 y 二也是一样的,那我在他的基础上,我加了一个 f, 送了二,我就得到他的一个真实的,这叫 y 二吗?所以每个样本 x 一到 x n, 我们都可以把它写成这种形式。 但是这里呢,当我把这些误差全部单独拿出来去观察的时候,而且我的 n 可能是比较大的,那我们会 通过中心极限定理,我们可以认为这些误差他其实可以服从一个正态分布,对吧?那这个正态分布呢?可能是以可能是类似于这样的一个正态分布,比如说 c 码的平方。然后我们在 这里假定的是它它的均值为零,因为有些误差呢,它是正向的,有些误差呢,它是负向的。所以当我的数据量很多的时候,我们可以认为 他的误差他的均值可能会服从零。但是我有一个类似于方叉,叫四个码的一个这样的一个方叉,然后呢,具体的模型的话,我们可以通过这个方式来表示。所以在这里呢,我们假定我的 apson 他是个随机变量, 然后这里的 f 送一到 f, 送了 n 呢,是这个随机变量的一个具体的一个展示的形态而已。 然后呢,这里的 fcelong 就服从一个零到 c 吗?平方的一个正态分布。所以现在开始,我们有一个很重要的一个思维的转变,就是把 fcelong 把它看作是一个随机变量,我们之前没有从这个角度考虑,但现现在开始呢,我们把 apsolon 就把它看作是个随机变量,然后这里的每个 f, x, l, e 到 x, l, n, 实际上就是随机变量的具体的某一个值,然后这个随机变量呢?它服从一个正态分布,那我们先记住到这里。
540文哲聊AI 15:14查看AI文稿AI文稿
15:14查看AI文稿AI文稿各位朋友大家好,呃,今天呢,我们呃向大家准备向大家讲解机学习的一些系列课程,然后今天我们当然是第一次课,然后呢我们讲的内容呢? 呃,主要是向你回归我们这个课程的系列课程的主要的目,目标呢?或者主要的想法呢?是向大家分享一下这些机器学习经典算法的一些他的原理呀,他的数学的一些共识的推倒呀, 然后他的一些具体的编程实现,然后呢使得在这个过程的讲解和代码展示当中,使得大家对这个算法有个更加具体的认识。呃,使得就是在算法具体 用的时候,比如说我们现在很多算法他的库都封装好了,我们在时代用的时候,呃,知其然也知其所以然,会有一个对算法一个更加深入的认识吧。 好,我们今天的课程呢是以线行回归来作为开始。呃,大概内容呢?主要是,呃下面这几点啊,一个是他的问题定义,问题求解以及他的数学上的解释。呃代码实现的可能到下个小结我们专门的来去向大家展现。 然后我们首先来看看现行回归问题的定义,在这个现行回归问题定义呃之前呢,我们首先要向大家简单的介绍一下积极学习的一些相关的一些背景知识啊, 或者背景概念。比如说首先什么叫监督学习,然后呢,呃,就是说监督学习呢,我们这个 对他赛才或者我们的数据级啊,就是因为统计学习嘛,他是都要从数据中去学习他的模式,而监督学习呢,就是他的数据模式呢是 xy 这种样式,这个 x 呢就是我们的输入特征, y 呢就是我们想要的结果。而我们这个对他赛的这个 y 呢,是我们用户 去进行标注,去进行 labo, 去进行 lab 领,去标注,然后告诉机器该怎么去学习这个目标,这个就是我们叫监督学习, 也就是告诉机器明确的需要学习什么。当然呃,和监督学习相对应的还有非监督学习,半监督学习,这个后续有机会再向大家去讲解。 就是比如说非监督学习,那肯定就是这个 y 就没有了吗?对吧?只有原始数据,他可能做一些剧类啊,对吧?做一些把他去进行那些,比如说 kines 或者其他的一些剧类,那就可能非监督学习。然后呢,我们 监督学习的目标呢,就是使得,就是呃一个函数,我们要学习一个函数,这个函数呢就是说 hapses, 然后呢他呢就是从 x 去应受到 y, 使得呢这个 x 和 y 的这个关系呢?尽可能的准确。这样的 这个 h x 呢,就是我们所要学习的这个目标。当然这个 s 呢,其实就是学习,主要就是学习这个函数的一些一些参数,对吧? permeters, 我们这个参数是要通过学习去学习到它的具体参数是什么。然后呢,我们建筑学习上面呢,主要有分回归问题和分类问题, 比如说回归问题呢,也叫做国家审啊,回归问题,比如说他呢,就是说他这个 h 呢,这个音是函数呢,他是连续的,而这个分类问题呢,叫克拉斯 k 审,他这个函数呢, 这个还是函数呢?是他的目标呢?是离散的,比如说连续的,就是比如说回归什么呢?比如说回归身高呀,对吧?回归这个面积啊,或者回归什么其他的。而这个分类呢,他是,比如说他回归是是 那个梨子、桃子、苹果,对吧?这是具体的这种这种类别,这个就是分类,就是一个回归,一个是分类。 我们今天讲的线性回归问题呢,首先他这个线性函数叫线性回归,首先他这个癌质函数是线性函数,线性函数当然相对于是比如说多项式、多元多项式、多元几次多项式,对吧? 然后还有指数函数这种性质,这个线性呢是相对来说比较简单的一种函数。然后呢我们接下来 就向大家介绍一下,比如说现行回归问题的求解,就是说他现行回归问题他怎么表示的?他的这个我们在在这个机器学习里面,一般都会定义这个 cos 的方式,或者叫 loss 的方式,就是大家函数是什么? 然后呢我们解解解解这个问题的方法,比如提出下降啊,或者是其他的一些一些分析分析的这种数学方法去直接求解。对,然后呢我们可以看啊,现在我们来看一下这个线性函数的表示是什么样子的呢?我们呢在这里可以看到这个线性函数呢 来用下笔啊,线性函数呢,其实我们在这里就用这样一种形式,这个 hctx, 这个 x 就是我们输入的这个特征,就是我们采集的数据的这个 这个数据的叫做 features, 对吧?也就是它是一个多维的数据,你在这里面我可以看到它是 x x 二,就是有两个维度嘛,对吧?嗯,然后呢这个 c 它呢其实就是我们需要学习的参数,在这里面的这个 c 大零, 我们可以要陷进函数吗?斯大林呢?其实就我们在这里面教,在在以前中学数学啊,或者是呃,数学里面呢?他这个叫做叫做什么?叫做洁具,叫做洁具。然后呢在这里面呢,我们把它叫做戴奥斯,对吧?戴奥斯偏执 偏指,然后呢这是现已函数的这个直接表示方法。当然如果你比如说他这个 x 的尾度很大,比如说一百个,那就要写斯大林一直到斯大林一百,对吧?这个就写球就不方便,这个里面呢,我们就用这个用求和工序 去写。然后呢这里个后面呢,我们就是一个项链的表达方式,他其实其实就是什么样子的?其实就是啊啊,随他零,按这边写吧, 就是 c 他零, c 他一, c 他二,对不对?然后呢 x 一 and 零 s 零就是一啊,在这里面就是相当于是是一个一嘛,对吧? s 一 x 二, 这就是项链的表达方式,就是两个项链相乘嘛,对吧?就是就是一个,比如说是个三一乘以三的一个项链,就是三乘以一的项链,两 项链相乘,最终的结果就是一个一个标量值,对吧?就是一乘以三和三乘以一,两个项链相乘,就是一个标量的值。好,然后呢这个怎么去根据我们的样本?比如说我们有一百个样本,那就有一百个 sg, 一百个 s 二,对吧?还有一百个这个 y 吗? 刚才所说的歪,怎么去把他的先行关系表示出来呢?比如说我们样本啊,就是说,比如说,呃,假设我们的目标是这样一个线吗?对吧?是这样一个线,然后呢我们采集的样样门点的有很多,当然采集的都是在就是这样的一些点,然后呢这个线 这些点,对吧?我们给了这一百个,然后这个线呢,我们通过这些点的这些坐标值,对吧?坐标值就是坐标值,按四和歪值就 就能直接的把这条线的这个参数学出来,这是我们的一个问题,然后呢这个问题怎么解呢?对吧?我们 c 大零, c 大一、四大二都不知道,那怎么解呢?这个时候呢,我们就提出了这个 cos 方式, cos 方式就是求解方法, 那这个修解方法是什么样子的呢?我们可以看一看啊,就是说我们这个高速方向呢,他其实定义了一个函数,他其实也是一个函数,他是从零到 m 个样本的一个可以看啊,就是说 五 h 就是他的假设值和他的真值这个 y 之间的一个差的平方,这叫做平方差,对吧?这叫平方差,就平方差的和平方差的和。这个这个公式呢,我们一般的也叫最小二长,对吧?最小二长公式,那这个为什么去 这么定义这个函数呢?对吧?使得这个函数最小 cose 就是代价,代价最小 的这个 c, 他的值就是求救助我们要求的这个 c 他的参数,那这个为什么要求这个最小呢?这个就能够表达这个 c, 他呢就能够去能够很好的去通过这个公式就能很好的求的这个 c, 他呢? 这个呢?我们后续的就是第三个部分会讲,就是他的概率解释部分会讲,然后呢我们可以看啊,这个,这个怎么去纠结这个公式呢?这个里面呢?其实就 用到了数学里面的偏倒数,对吧?我们这个是是一个 c, 它是一个项链的,对吧?我们 c 它对每一个 c 它的一个,它对应的这个维度有偏倒,在这个函数就会得出这个 偏倒数的这这样一个值,就是偏倒数是这样的一个值。然后呢我们通过什么方法呢?这个偏倒数算出来以后其实就是一个项链啊?就是 就是这样意思,我我们画了一个倒三角,对吧? c 他这个项链呢,其实就是这个 c 他的一个梯度,在在高速里面这个叫梯度。 那我们最终的这个就是说,呃,在这里面所要向大家介绍的这个算法呢,其实就是叫做梯度下降算法,就是随机梯度下降算法,或者叫做批量梯度下降方法啊,就是说这个他这个 c 他呢他是个迭代求解的,也就是说我们 c 他零 c 二,就是说 c 二第零次,我们初始化这个参数,对吧?我可以负为任 力的处置化,相对都可以,比如说我们就开始就可以为零零零三个零,对吧?然后呢我怎么去中国迭代?比如说迭代一万次, 接待一万次之后,这个 c 他就是我们求的这个目标呢?这里面呢就是每一步接待是怎么求的?就是通过这个与就是上一步的这个 c, 他结果加上这个阿尔法呈上这个梯度,这个阿尔法呢就要学习力,叫 learning rate, 这就是我们所要求解的一个方法,它叫做梯度下降法,也是一个迭代求解的一个过程,当然这个因为我们这个函数呢,其实它是可以通过这个数学叫做分析的方法去直接通过公式来求的,通过 现行代数的一些公式来求。但是这个在这里面呢,我们就就不讲了。对,这是我们的这个 线线回归问题的一个就是表示方法以及他的求解方法,就是然后呢我们再看一看,就是刚才所说的,对吧?就是这个这个公式, 为什么可以他用他来求,他求他的最小词就可以表示,这个就可以得出现行回归的这个解法呢?他其实是在统计上啊,就是概率统计上是有他的这个可以解释的地方的这个解释的。呃,下面我们就具体向大家解释一下,比如说, 呃线性函数的表示呢?呃,刚才所说啊,就是说因为刚才我们可以看到,其实我们在收集数据的时候,这个数据其实并不是说严格的在一条线上,对吧?那现实中我们在我们的这个物理世界当中收集的数据不可能那么 么的就是没有,没有偏差或者没有噪声,对吧?这个时候呢,我们就可以看到这个 y 呢,其实是 ct ts 加上一个 epos, 这个 epos 通的其实其实是服从这个高斯,就是均值为零这个方叉为 segamara 的这个高斯分布的 这个呢?这个高斯分布一般的啊,就是说可以就是因为他这个我们建国的比如说因素并没有考虑全,对吧?就是说没有考虑全的这个因素里面叠加起来他就是一个高斯的一个分布,这个是数学上也可以解释的,然后呢这个求解方法呢? 刚才所说啊,就是说呃呃呃,就是刚才的方式求解的方法呢?就是呃这个噪声它服从高斯分布,对吧?就是服从 这个 epston v, 就是君子为零,是方叉维斯科的 c 吗的这种高速分布,然后呢这个 y 指呢?同力,对吧?就可以转化一下,他也是服从高速分布的,服从高速分布的,这是一个样本,对吧?这是一个样本,就是 y i 这个样本,那所有的样本, 比如说我们收集了一万个样本,那或者说收集了一一百个样本,对吧?这一百个样本他的联合分布, 对吧?就是因为我们现在所有的样本都是独立同分部的,也就是说我们抽取的时候抽取每个样本都是独立抽取的,他不依赖于 上一次的抽取,或者是以后的某一次抽取他都是独立的,所以说这个叫做独立同分部的话,他的联合概率其实就是每一个概率的成绩,就是 是每一个概率的成绩,就是这个连成,对吧?然后这个连成其实表达结果就是这样,然后呢这个连成的公式呢?去求他的这个这个这个这个概率呢,就是说 不太好求,对吧?因为这个概率呢联合概率分布呢?一般的因为需使得就是说现实世界中这个 这个要你和这个统计的数据的话,那就说明这个统计数据分布是这个分布的话,他这个联合概率分布应该是 是取最大的,就是就是最大四然函数,对吧?就是最大四然函数,而而使得这个函数最大呢?不太直接好求,这个时候呢我们就需要就是有一个就是转换的方法,把它求 log, 求 log 的话这个连成呢,就可以把它转成连加, 对吧?人家然后去对应的去转化,这个转化呢?这这个值呢是长数值,这个值也是长数值,对吧?然后就是一个负的二分之一,这个这个负的二分之一,这个 平方差这个负数呢?就是说你因为求这个概联合概率吗?就是自大自大自然函数吗?他最大的话加了一个负值,所以说就相当于,是吗?相当于这个正值要求最小,对吧?就是这一部分 去掉符号这一部分二分之一,这个这个最小,这个最小呢,就是和上面的这个是一样的,就是求这个 cos 方式最小,这个其实就是用联合概率分的自然自大自然函数去解释这个公式。 对,然后就是具体的这个我们讲解的部分呢,就到这里。然后呢下一部分呢,我们就会讲一些大 实现,主要从当派的实现和派大使的实现去给大家展示,我们这次的小课呢,就到这里,谢谢大家。
760和森致远知识社区 10:58查看AI文稿AI文稿
10:58查看AI文稿AI文稿啊,大家好啊,欢迎继续学习三小数据分析基础系列技巧视频 啊,今天呢应很多人的要求呢啊给大家简单讲解一下在这里边呢回归分析的做法啊,回归分析呢,实际上是数据分析里面非常核心的经典呢,或者说是据 基础性的一种这个数据分析方法啊,很多高级复杂的模型的,实际上他都是建立的回归模型的基础之上的,而回归本身呢,又有分为很多种啊,这个我们马上就要讲的这种线性回归, 还有的这种这个逻辑回归啊,二分的逻辑回归,多分的逻辑回归啊,还有多像是的这种回归领回归 n 多的回归的方法啊,举几个例子,呃,所以呢,呃他是非常庞大的一个体系,而且 呢在做回归分析之前呢,我们还要满足他几个假设啊,就是啊方差其性啊,然后数据的这种正态分布正态性啊,还有这种观察独立性 n 多的这种假设啊,但是在实际应用过程里边呢,我们很难取到说完全符合他的前提假设的一些数据, 所以这个时候呢就需要啊,我们用模型的一些检验,像啊,模型里面有很多的检验功能啊,来去观察和弥补我们这个原始数据的对于满足假设的一些缺陷 啊,这个呢东西呢,要要深讲的话就是很复杂的一些东西啊,我们今天呢因为 style 呢也是看一下最基本的功能就可以了啊,对于大部分人来讲的话呢,呃,如果你不是去做数据建模的话啊,或者说去做非常精准的预测分析的话呢,呃基本就够用了啊,好,我们来看 看下我们这个数据啊,这里边呢,我们有啊,一个外变量啊,这是我们的这个音变量啊,两个 x 变量,就是两个自变量。呃,第一个自变量的 x 一呢,就是市场投入预算啊,就是做活动的啊,自己拉客户拉新啊,做活动,做促销, 然后这个呢是我们企业所拥有的客户的总数啊,这个总的客户基数,然后呢这个这两个因素会影响到我们客服中心每天的会接听的电话的量啊,师傅,这这个 量不是每天的啊,这个量应该是月或者是季度啊,就类似的,我们单位就不管了啊,基本上就是这组数据就可以了啊。好,我们这个数据准备好之后呢,我们来找到数据菜单,然后呢数据分析,再强调一下,如果还是找不到 数据分析菜单的话呢,翻我前面的视频啊,去自动加载啊,然后呢我们找到里边的回归啊,回归,然后呢确定 好 y 啊, y 呢,就是我们这一列啊,这一列,所以我选中 c 一,然后呢卡出 shift 下箭头, c 一到 c 三十六, x 呢,就是我们的这个前边 ab 两列,我选中 a, b 一 看出 shift 下箭头啊,注意 xty 的这个数据要对称啊,要对称,都是一到三十六啊,这里边呢,我们的第一个单元格,就是每一列的第一个单元格都是标题,所以我们要勾上标志啊, 就是告诉 excel 呢,第一个单元格第一行并不是数据执行度,默认百分之九十五就可以了。然后呢输出区域,我们把它放在这个当前工作表啊,就默认 的话他是新工作表,现在我们把它放在当前工作表,我们把它放在 f 一就可以了啊,就这样一个设定就可以了,然后点确定好啊,这就是我们的这个回归的结果啊,我把我们应该注意的东西呢啊,简单标一下啊,给大家做一个解释, 这是一个地方,然后这是一个地方啊,然后呢是我们这两个是一个地方, 然后这是一个需要注意的地方啊,我看一下啊,好,我把 哇这几个地方呢给大家解释一下啊。这个首先呢我们看二方,二方呢实际上是说,呃,这些变量啊,就是我们两个 x 变量对外的这个影响程度啊,也就是说他能够决定 外的多少的变化啊。实际上这个这个数据很夸张的,一般我们到不了这么高,因为这个数据是模拟数据啊,百分之九十九,也就是说 x 跟哇这两个 x, 一个是客户基数,一个是市场投入预算呢啊,基本上是百分之百的影响我们画量的变化啊,所以如果你要预测未来的话,量的话呢,你就盯这两个变量就可以了, 这是最理想的一个结果,但实际上呢应该是我们很难达到这么高的一个精度啊啊,然后呢啊,接下来呢,我们实际上如果当你的 x 不是一个啊, x 多于一个的时候,比如说我们 这个例子啊,就是两个 x, x 应该 x 二 x 一,市场投入 x 二呢是客户基数,我们更应该看的不是上面的 r 方,而是看调整后的 r 方啊,这是因为这个回归模型的有一个惩罚机制啊,就是我们随着我们变量数量的越来越多,现在我们俩 变量,我们有时候可能会遇到三个变量,四个变量,甚至五个变量,六个变量,这个变量啊,就是他本身啊,尽管跟外之间的关系啊,没有关系,或者是关系不明显的话呢,随着我们自变量的增多, 滥竽充数的效应他也会加大,我们这个什么这个像这个总体的这个跟外的相关性。所以在回归模型里边呢,有一个惩罚机制啊,就是我们的 调整后的二房啊,就是要对这个根据我们自便量的这个数量啊,进入到模型的数量的去对他有一个惩罚机制啊,去调整调低 啊。所以从这个理论上来讲啊,这个你经常看到的现象是说我们调整后的儿方呢,总是会低于这个单纯的儿方值啊,所以对于 x 变量大于一的啊,就是从二开始,二三一直往上到 n 的,我们更应该看的是 调整后的二方,而不是单纯的看这个二方啊。如果你只有一个变量啊,就是一个 x, 然后一个 y 的话呢,你看二方啊,调整后的二方应该是一样的 好,这是第一个要注意的地方。然后呢观测只能有三十五个啊,这是我们一共是有这个三十五个数据量啊,是这个数据观测记录。 接下来呢,我们来看这个方差分析, f 检验啊, f 检验这个地方呢,我们的这个要牵扯到统计学里边一些基础知识,就是你的背则假设和这个原假设,我们的原假设是说这两个 x 跟 y 之间都没有关系啊, 这两个 x 跟 y 之间都没有关系,就是他们的这个整个的这个啊,斜率的应该是为零啊,背则假设呢,就是说,呃,我们这两个变量, x 跟 y 之间至少有一个不是 a, a 和 b 啊, a 和 b 啊,就这两个,这两个跟这个 c 之间啊,跟这个联络量之间至少有一个变量是跟这个我们的联络量是有关系的,也可能是两个,也可能是一个啊,至少有一个 啊,是这个跟我们的这个音变量是有明显的关系的。这是贝泽假设啊,这个判断依据呢,就是我们那个著名的零点零五啊,就是那个著名的零点零五的那个那个线垂直啊,零点零五 啊,怎么样去看这个数啊?有人看到这个数就傻了,这个数是什么东西啊?这个数呢?就是科学计数法啊,教我,教给你一个最容易记的方法,看到易后边如果是负三十五就意味着什么呢?这个小数点,一点零五零一点零五四零,这个地方,这个小数点啊,负三十五就意味着这个小数点往左挪三十 十五位啊,往左挪三十位,实际上是十字三十负三十五之方,这个数据已经很小很小啊,趋近于零了啊,所以他一定是小于零点零五的,也就说明这两个变量, a 变量和这个 a 列,这个变量和 b 列,这个变量啊, 至少有一个,或者说是两个都和 c, 就是和我们的连热量这个音变量有非常强烈的这种关系啊,这个相关关系 啊,这个数越小就证明我们的 x 对 y 的影响呢,是越显著啊,就是这个,你要知道这一点就可以了,然后这一点判断过了啊,上面这个判断啊,这个相关性很高,然后这个判断呢,这个呃 远远小于零点零五,之后呢,我们才可以放心的去看下边啊这一块,这块呢你主要看两个变量的批值就可以了啊,这个市场投入,市场投入的这个批值呢啊,这个地方也要小一点点 零五啊,零点零五就证明他对这个外,就对我们的这个画量啊,结果变亮的有一个显著性的影响,这两个就仔细一看都是负十六,负零六,也就小视角往左挪六位,小视角往左挪十六位啊,远远小于零点零五, 这个时候呢我们就可以放心的讲啊,这两个 x 对我们的最终的话量啊,联络量啊,这个对对我们外呢是有显著性的影响的啊,这个通过的,这个整个的检验的就通过了啊, 这样最后呢我们这个三处检验啊,这边啊相关性足够高,然后这边呢是元元性零点零五,然后这两个变量单独呢都是这个跟外之间的,跟我们的这个音变量之间有显著性的这个相关关系。好,下面呢我们就可以来用这个回归系数呢来去写这个方程 了啊,方程写出来啊,怎么写呢?就等于外啊,等于我们的这个第一个是零点八四四二五九啊,零点八四四二五九,他要乘以 啊,他要乘以市场投入啊,摄像头那个万我就不写了啊,我那个万我就不写了,然后加上一个什么一点零一的亿,负零五他要乘以什么呢?他要乘以我们的客户计数 啊,客户计数,然后最后呢再加上我们的这个的洁具啊,幺幺七四点五七二,这样我们的这个 线性回归方程呢,就写出来了啊,这个就是我们的整个的简单的回归的分析啊,包括回归方程的这种声称啊 啊,再次强调啊,在真正的这个我们去做,如果你是去做非常严谨的科学研究啊,甚至是医学研究的时候呢啊,这些检验呢,仍然不够啊,最好是把它这个同样的数据呢转到更加专业的工具上啊,这个像 sps 啊,或者说其他的一些这种专业工具 啊,去做这个什么这个贡献性的检验啊,自回归的检验啊,类似这些其他这些检验啊, dw 测试啊啊,那样的话才能确保我们的模型呢啊,更加的完整无误。在 excel 里边呢,我们是只能看一个大概 啊,就是应该是问题不大,但是呢啊,仍然是缺一些非常严谨的一些测试。好啊,这一节呢就给大家讲解到这。
2062数据分析精选 01:53查看AI文稿AI文稿
01:53查看AI文稿AI文稿上期视频我们介绍了如何在 spss 上进行多重线性回归操作,并对运算结果进行了解读。本期视频我们继续来学习线性回归模型的诊断。 线性回归模型的运算有三个前提条件,即样本独立、残叉正态和自变量不存在多重共线性。只有满足了以上三个条件,那么之前得出的线性回归结果才是准确可靠的。 第一,样本独立性的判别及各样本之间不会相互干扰,通过模型摘药表中的得兵沃森及 dw 值来判别。如果 dw 值在二附近,意味着样本独立,本案例的 dw 小于二,但是偏差也不是很大,存在轻微的非独立性,但是影响不大,不会太影响回归结果的准确性。 第二,残叉正态的判别及模型的残叉服从正态分布。在直方图中,黑色曲线为正太曲线,而黄色柱子的轮 扩远远高于正态区线,意味着本次模型的残差不服从正态分布。出现这种情况的主要原因是模型你合度二方不高,自变量只能解释因变量变异的百分之十一点四。解决这个办法的问题是还要再多加入几个自变量提升模型的你合度,那么残差就会接近正态分布。 至于在加什么样的自变量,还需要大家根据自己的专业知识考察,加入一些极有可能会影响心率变化的自变量。 第三,自变量不存在多重贡献性的判别。通过系数表中的 v i f 值来判别。 v i f 值小于五,意味着变量之间不存在多重贡献性,不会影响回归结果的准确性。 对于经济类数据,关联性本来就很强,这是这个行业决定的。因此有些经济类数据 vif 的临界点可以放宽到三十多,都认为不存在多重贡献性。综合以上的现行回 规模型的诊断,可以得出回归模型的结果基本准确,可以基于这个结论给出相关的对策建议。最后,以上回归模型的结果可以采用 graphic present 会图进行可视化处理。
185追梦吧,少年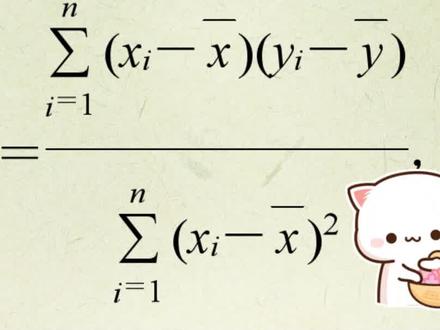 20:01
20:01 01:13查看AI文稿AI文稿
01:13查看AI文稿AI文稿本期案例的研究目的为探寻年龄 bmi 是否会影响心率。我们搜集了一百六十五名正常人的年龄 bmi 心率数据,数据情况如下, 具体在 spss 上操作为,第一步,点击分析回归线性。第二步,选择对应的自变量和应变量。第 三步,点击统计贡献性诊断得兵沃森,然后点击继续。第四步,点击图,按照图式进行选择,然后点击继续。最后点击确定 spss 软件就会输出多重现性回归的运算结果。 结果解读模型摘要表显示,二平方等于零点一一四意味着自变量年龄和 bmi, 可以解释因变量心率变化的百分之十一点四一八二言二方,在百分之三十以上意味着你和状况良好,而实际数据分析百分之十也是可以接受的。系数表显示年龄显著负向影响心率, 影响系数为负零点一八四,小于零且显著性 p 等于零点零零零,小于零点零五意味着年龄越大心率越小。 bmi 显著正向影响心率,影响系数为零点七四四,大于零且显著性 p 等于零点零零五,小于零点零五意味着 bmi 越大心率越大。基于系数表的结果得出回归方程心率等于六十五点七八八,减零点一八四成年龄加零点七四四 bmi。
763追梦吧,少年 03:18查看AI文稿AI文稿
03:18查看AI文稿AI文稿相关性完了之后,然后再进行回归,就是真正的构造方程,他们之间有一个什么样的方程的关系?怎么操作呢? 这里啊, y 因为是应变量,我们习惯性的写,但是写成 y 等于 ax 一加 ax 二, y 是不是第一个要写?所以你 y 要第一个点,然后按照顺序点,然后直接点右击,然后这里不要点彝族打开啊,这里有一个以方程打开,点击以方程打开,这里就构造好了。方程不需要你输入任何的东西, 然后面也不需要你输入任何的东西,这是最简单的一个会方程形式,然后你直接点击默认的确定就行了。然后这里就输出了这样一个 表格,这个表格大家可以看一下。呃,我照着念一下吧,大家写的时候照着这样写就行了。就通过表格可以看到变量 x 一的估计系数就这个前面的系数为负的零点六三,然后他的 t 值是零,负的零点二零八三,然后 p 值就是零点八三, 对吧?他在百分之五的,他大于零点零五吗?所以在百分之五的显著性水平下,质变量 x 一对应变量 y 没有显著影响,就他并不是显著的,他可能概率太小了, 他能影响他的概率太小了,那是什么原因呢?嗯,咱们后面再说,有可能是因为 xr 在这里干扰他,或者是 s 三在这里干扰他,甚至 x 一他本身自身就有问题,他要被去除。然后。好,咱们再来看变量 sr, 他的估计系数为二点五八,然后他的对应的 t 值是零六点七八,然后 p 值是零点零零零, 小于零点零一,所以在百分之一的显著性水平下,质变量 x 二的应变量是显, y 是显,影响是显著的,对吧? s 三也是这样的估计方式,大家就可以看到只有 s、 r 和长数像是显著的,其他两个变量他是不显著的,对吧? 然后说一下这几列的关系啊,这个梯子是怎么求的的?七梯子就是系数值除以除以这个标准差 等于系梯子,然后坯子他有一个梯子的对照表,就像以查字典一样,你去百度梯子的那个借纸表,然后就可以查出坯子的这个对照像,有点类似于查字典的样式,我们不需要就是说呃,怎么去查,因为软件都给你算好了,知道他是怎么来的就行了。 然后这里,这里是调整后的啊方,啊方是什么意思?啊?方就是这几个 x 一、 s 二、 s 三他们加起来能够解释百分之多少的 y, 就这个他解释解释的力度越大越好,最大的值为一。也就是说如果 s 二、 s a 一、 x 二、 x 三,他们三个人加起来 一起解释这个外,比如说我说这个人很好,呃,他怎么好,他学习好,他大人真诚,他诚恳,他对应的就是 x 一、 x 二、 s 三。大家想一下,在日常生活中,我们说一个人好,我们能用一个 词组词汇把这个人的好能完全的概括吗?他总有遗漏吧?你说他学习好,待人真诚,呃,热情,乐于助人, 那,那别人还说他体育成绩好呢,还会篮球,打得好了,人长得帅了,会关心人了你,你后面的这些你都没有说到啊,你可能只说到了前面的 s 三呢, 但是啊,你,但是你 x 三如果解释到了百分之九十九,那说明你这三个变量已经解释的很好了。就这个意思,他越越高肯定就是越好的,但是永远都不可能唯一,因为你总有遗漏的 底下的这个 p 值,他检验的是整个模型的礼盒程度,这个这个后面的每一个系数,后面的 p 值只检验了单个的系数,然后对应的 p 值是零点零零零,小于零点零一,所以在百分之一的显著性水平下,自变量对应变量具有显著影响。这个时候说的是自变量对应变量,而不是说的某一个自变量的啊,就是说整个方程的情况。
998数知






猜你喜欢
最新视频
- 1.4万尹烨